Tidy Text, Tokenization & Term Frequency
Text Mining Module 1: A Code Along
Welcome to the Text Mining Code Along for Module 1
The Text Mining course is designed for those seeking an introductory understanding of quantifying the text in documents to better understand their properties.
The following Code Along is a companion to the Module 1 case study’s Prepare and Wrangle stages.
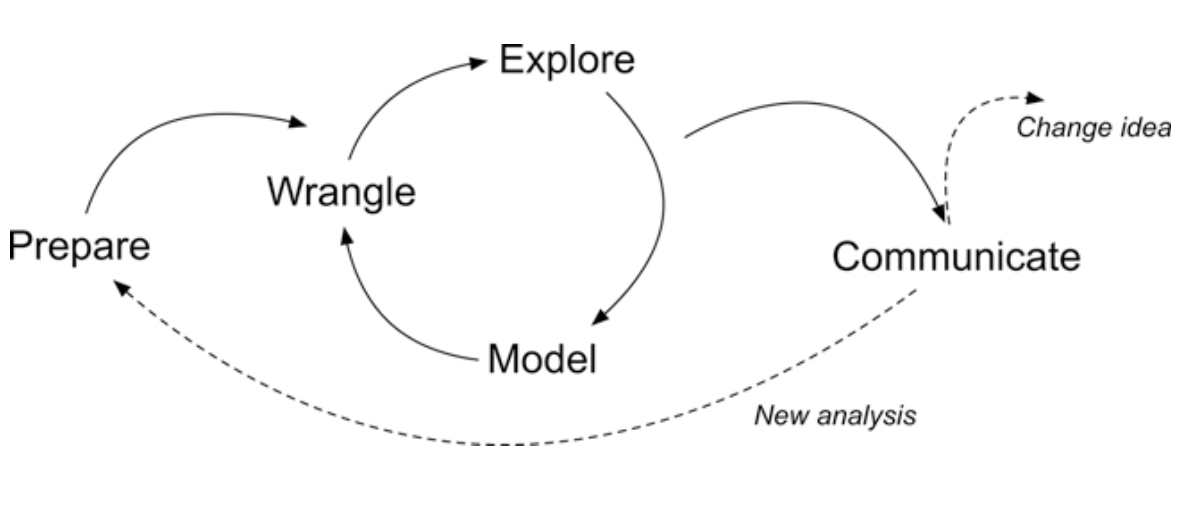
Figure 2.2 Steps of Data-Intensive Research Workflow
[@krumm2018]
Load Libraries


- Load the
tidyverseandtidytextpackages usinglibrary()
Reading Data, Cont.
To get started, we need to import, or “read”, our data into R
The RttT Online PD survey data is stored in a CSV file named opd_survey.csv which is located in the data folder of this project
Use
read_csv()to saveopd_survey.csvas a new objectopd_surveyThis file can be found in the local data folder
If you have questions about the above function, don’t be afraid to look it up in console using
?read_csv()
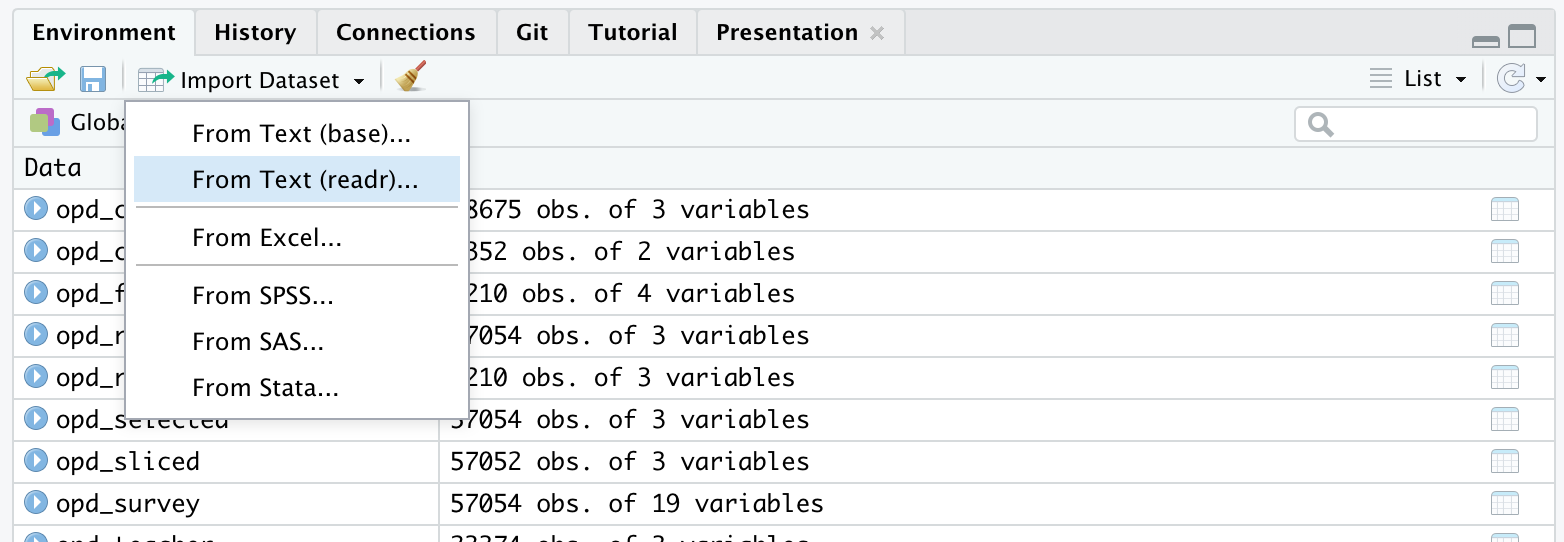
- There is also an Import Dataset feature under the Environment tab in the upper right pane of RStudio
unnest_tokens()
The unnest_tokens() function transforms our opd_teacher text data from this…

… to this!
Use
unnest_tokens()to tokenizeopd_teacherinto new objectopd_tidyWithin the function, follow the table
opd_teacherwith theoutputandinputarguments aswordandtext, respectively
Remove Stop Words
One final step in tidying our text is to remove words that don’t add much value, such as “and”, “the”, “of”, “to” etc.
The
tidytextpackage contains astop_wordsobject, which is a list of generally agreed-upon “not useful” tokens, which we can use as a filter.
Here are some of those words:
# A tibble: 20 × 2
word lexicon
<chr> <chr>
1 a SMART
2 a's SMART
3 able SMART
4 about SMART
5 above SMART
6 according SMART
7 accordingly SMART
8 across SMART
9 actually SMART
10 after SMART
11 afterwards SMART
12 again SMART
13 against SMART
14 ain't SMART
15 all SMART
16 allow SMART
17 allows SMART
18 almost SMART
19 alone SMART
20 along SMART anti_join() looks for matching values in a specific column from two datasets and returns rows from the original dataset that have no matches.
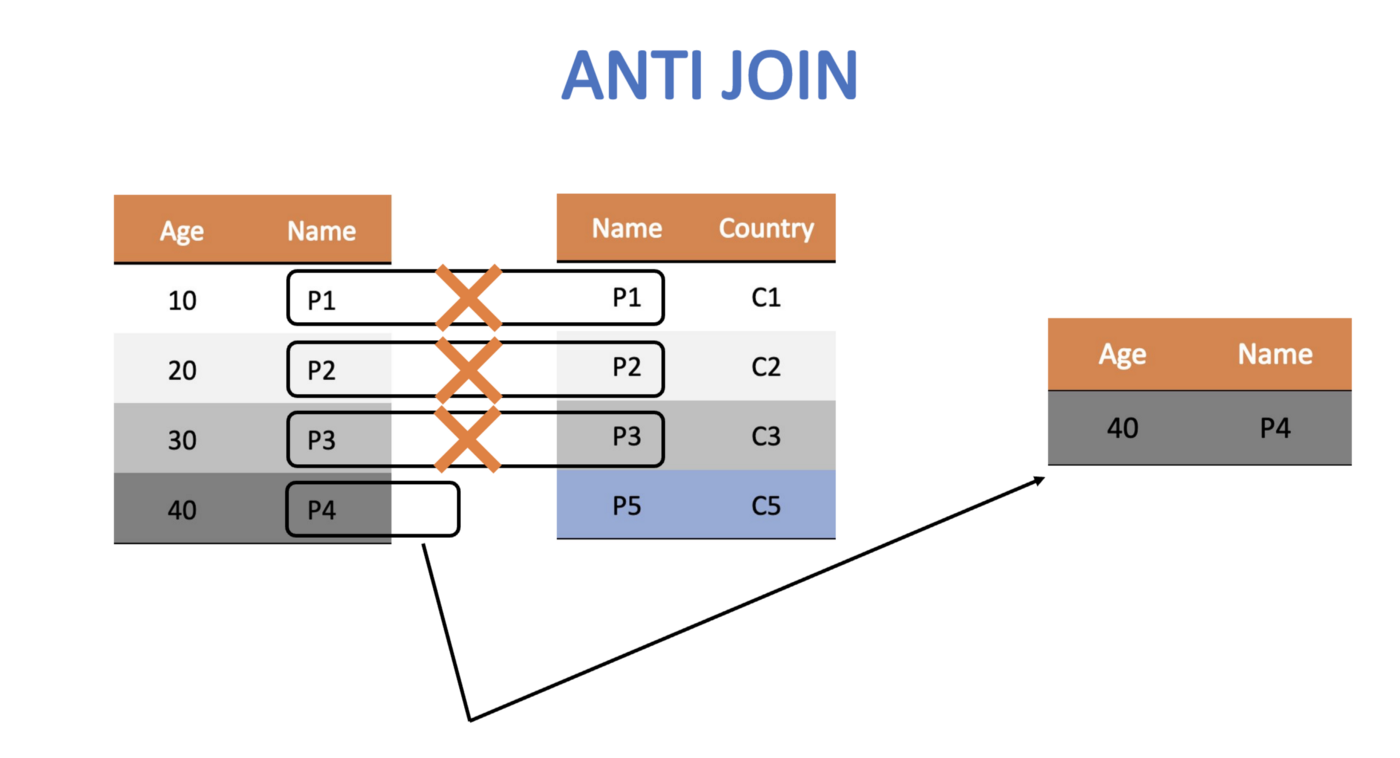
- Use
anti_jointo remove the rows fromopd_tidythat contain matches in thewordcolumn with those in thestop_wordsdataset - Save it as
opd_clean, since this is the final step in cleaning for this exercise
# A tibble: 78,675 × 3
Role Resource word
<chr> <chr> <chr>
1 Teacher Live Webinar levels
2 Teacher Live Webinar ofquestioning
3 Teacher Live Webinar revised
4 Teacher Live Webinar blooms
5 Teacher Online Learning Module modules
6 Teacher Online Learning Module teacher
7 Teacher Online Learning Module shown
8 Teacher Online Learning Module action
9 Teacher Online Learning Module classroom
10 Teacher Online Learning Module modeling
# ℹ 78,665 more rows