Having fit and interpreted our machine learning model, how do we make our model better? That’s the focus of this module. There are three core ideas, pertaining to feature engineering, resampling, and the random forest algorithm. We again use the OULAD data.
Having discussed ways of interpreting how good a predictive model is, we can consider how to make our model better, having a rigorous framework for answering that question.
How good is a good enough model for which metrics?
Key Concept #2: Feature Engineering (Part B)
How?
Well, what if we just add the values for these variables directly
But, that ignores that they are at different time points
We could include the time point variable, but that is (about) the same for every student
OULAD interaction data is this way: the number of clicks per day
This data is sometimes called log-trace or clickstream data
In this module, we focus on using OULAD data on interactions data, the most fine-grained data
More Techniques
Removing those with “near-zero variance”
Removing ID variables and others that should not be informative
Imputing missing values
Extract particular elements (i.e., particular days or times) from time-related data
# Sample data with timestampstime_data <-tibble(student_id =rep("student_001", 100),timestamp =seq(from =as_datetime("2023-09-01 08:00:00"), by ="2 hours", length.out =100),activity_type =sample(c("forum", "quiz", "resource"), 100, replace =TRUE))# Recipe for time-based feature engineeringtime_recipe <-recipe(~ ., data = time_data) %>%# Extract date componentsstep_date(timestamp, features =c("dow", "month", "decimal")) %>%# Extract time components (hour of day)step_time(timestamp, features =c("hour")) %>%# Create holiday indicators (if relevant)step_holiday(timestamp, holidays = timeDate::listHolidays("US")) %>%# Remove original timestampstep_rm(timestamp)# Prep and bake to see resultstime_features <- time_recipe %>%prep() %>%bake(new_data = time_data)# Show first 5 rowstime_features %>%head(5)
# Split our simulated data for trainingoulad_split <-initial_split(simulated_oulad, prop =0.8, strata = final_result)oulad_training <-training(oulad_split)oulad_testing <-testing(oulad_split)# Comprehensive OULAD feature engineering recipeoulad_recipe <-recipe(final_result ~ ., data = oulad_training) %>%# Remove non-predictive variablesstep_rm(id_student, code_module, code_presentation) %>%# Handle missing valuesstep_impute_median(all_numeric_predictors()) %>%step_impute_mode(all_nominal_predictors()) %>%# Create interaction features (if relevant)step_interact(terms =~ gender:age_band) %>%# Handle categorical variablesstep_dummy(all_nominal_predictors(), one_hot =FALSE) %>%# Feature selection and preprocessingstep_nzv(all_predictors()) %>%step_corr(all_numeric_predictors(), threshold =0.9) %>%# Final standardizationstep_normalize(all_numeric_predictors())# Create workflow combining recipe and modeloulad_workflow <-workflow() %>%add_recipe(oulad_recipe) %>%add_model(multinom_reg() %>%set_engine("nnet"))# Fit the workflowoulad_fit <-fit(oulad_workflow, data = oulad_training)
Key Concept # 2: Resampling and cross-validation
Training data
In earlier modules, we fit and interpreted a single fit of our model (80% training, 20% testing). What if we decided to add new features or change existing features?
We’d need to use the same training data to tune a new model—and the same testing data to evaluate its performance. But, this could lead to fitting a model based on how well we predict the data that happened to end up in the test set.
We could be optimizing our model for our testing data; when used with new data, our model could make poor predictions.
Resampling
In short, a challenges arises when we wish to use our training data more than once
Namely, if we repeatedly training an algorithm on the same data and then make changes, we may be tailoring our model to specific features of the testing data
Resampling conserves our testing data; we don’t have to spend it until we’ve finalized our model!
Resampling Process
Resampling involves blurring the boundaries between training and testing data, but only for the training split of the data
Specifically, it involves combining these two portions of our data into one, iteratively considering some of the data to be for “training” and some for “testing”
Then, fit measures are averaged across these different samples
k-folds cross validation (KFCV)
One of the most common forms of resampling is k-folds cross validation
Here, some of the data is considered to be a part of the training set
The remaining data is a part of the testing set
How many sets (samples taken through resampling)?
This is determined by k, number of times the data is resampled
When k is equivalent to the number of rows in the data, i.e. “Leave One Out Cross-Validation” (LOOCV) — typically not recommended
KFCV Example
# A tibble: 2 × 3
id var_a var_b
<int> <dbl> <dbl>
1 1 0.868 0.0797
2 2 0.621 0.845
Using k = 10, how can we split n = 100 cases into ten distinct training and testing sets?
First resampling
train <- d[1:90, ]test <- d[91:100, ]# then, train the model (using train) and calculate a fit measure (using test)# repeat for train: 1:80, 91:100, test: 81:90, etc.# ... through the tenth resampling, after which the fit measures are averaged
Determining k
But how do you determine what k should be?
A historically common value for k has been 10
But, as computers have grown in processing power, setting k equal to the number of rows in the data has become more common
Though, again, LOOCV (k = to the number or rows) is typically not recommended, as it can take considerable time and may have some undesired statistical properties
Key Concept #3: Random Forest and Boosting
Background
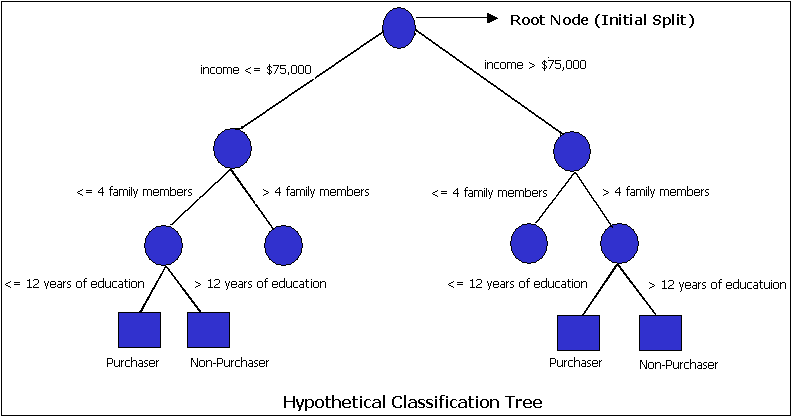
Random forests are extensions of classification trees
Classification trees are a type of algorithm that use conditional logic (“if-then” statements) in a nested manner
For instance, here’s a very, very simple tree (from APM):
Algorithm
if Predictor B >= 0.197 then
| if Predictor A >= 0.13 then Class = 1
| else Class = 2
else Class = 2
Measures are used to determine the splits in such a way that classifies observations into small, homogeneous groups (using measures such as the Gini index and entropy measure)
More Complexity
if Predictor B >= 0.197 then
| if Predictor A >= 0.13 then
| if Predictor C < -1.04 then Class = 1
| else Class = 2
else Class = 3
As you can imagine, with many variables, these trees can become very complex
Tuning
There are several important tuning parameters for these models:
the number of predictor variables that are randomly sampled for each split (mtry)
the minimum number of data points required to execute a split into branches (min_n)
the number of trees estimated as a part of the “forest” (trees)
These tuning parameters, broadly, balance predictive performance with the training data with how well the model will perform on new data
A boosted tree may achieve even better performance
Tuning starting points
Tuning knob
What it controls
Typical starting point
trees
How many trees to grow (more = lower variance)
500–1,000
mtry
How many predictors each split can peek at
√ p (classification) or p/3 (regression)
min_n
Smallest allowed group size to keep splitting
1–10
Key Points
A Random forest is an extension of decision tree modeling whereby a collection of decision trees are sequentially estimated using training data - and validated/tested using testing data
Different samples of predictors are sampled for inclusion in each individual tree
Highly complex and non-linear relationships between variables can be estimated
Each tree is independent of every other tree
For classification ML, the final output is the category/group/class selected by individual trees
For regression ML, the mean or average prediction of the individual trees is returned
Works well “out of the box,” handles quirky patterns, and is hard to over‑fit when you grow enough trees.
What Makes Boosting Different?
Instead of independent trees, boosting builds trees one‑after‑another.
Each new tree focuses on the records the previous trees got wrong—like a tutor giving extra help where you struggled.
When done carefully (small steps, many trees) the model can become very accurate.
Boosting in Four Plain Steps
Start simple: Make a tiny tree (a “stump”) that gives rough predictions.
Check mistakes: See which cases were predicted poorly.
New tree, new focus: Build another small tree that tries to fix those mistakes.
Repeat & combine: Add hundreds or thousands of these small‑step improvements.
A learning rate decides how big each correction is (small rate = safer, needs more trees).
Common XGBoost Settings to Try
Parameter
Meaning
Safe first guess
trees / n_estimators
How many rounds of boosting
300–1000
learn_rate
How big each correction step is
0.05
max_depth
Depth of each small tree
3–6
subsample
Fraction of rows used per tree
0.7–1.0
colsample_bytree
Fraction of columns (predictors) per tree
0.7–1.0
Rule of thumb: Lower learn_rate → use more trees; higher learn_rate → fewer trees (riskier).
Random Forest vs. Boosted Trees
Question
Random Forest
Boosted Trees
Speed to get a decent model
Very quick
Slower (needs tuning)
Risk of over‑fitting
Low
Medium–high if you crank settings
Best raw accuracy
Strong baseline
Often wins once tuned
Parallel training
Easy (trees independent)
Harder (sequence)
When to pick
Need robust, “just work” model
Willing to tune for top performance
Take‑Home Messages
Random forests fight over‑fit by averaging many diverse trees.
Boosted trees fight errors by learning from them in a smart sequence.
Both models need cross‑validation, but boosting needs more patience with hyper‑parameter tuning.
Start with a random forest as a baseline; move to boosting if you need extra accuracy and can spend some tuning time.
Baker, R. S., Esbenshade, L., Vitale, J., & Karumbaiah, S. (2023). Using demographic data as predictor variables: A questionable choice. Journal of Educational Data Mining, 15(2), 22-52.
Bosch, N. (2021). AutoML feature engineering for student modeling yields high accuracy, but limited interpretability. Journal of Educational Data Mining, 13(2), 55-79.
Rodriguez, F., Lee, H. R., Rutherford, T., Fischer, C., Potma, E., & Warschauer, M. (2021, April). Using clickstream data mining techniques to understand and support first-generation college students in an online chemistry course. 11th International Learning Analytics and Knowledge Conference (pp. 313-322).
Using (filtered) interaction data (whole data here)
Adding features related to activity type
Once again interpreting the change in our predictions
Considering the use of demographic data as features
Adding activity-specific interaction types
fin
Dr. Joshua Rosenberg (jmrosenberg@utk.edu; https://joshuamrosenberg.com)