Data Collection & Quality
SNA Module 2: A Conceptual Overview
A Quick Refresher
Network Theory
Social relations are often more important than individual attributes.
Social networks affect individual beliefs, perceptions, and behaviors.
Relations are not static but rather occur as part of a dynamic process.
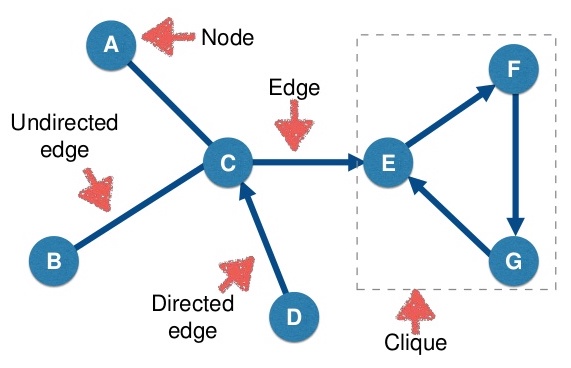
Network Terms
Acknowledgements

This work was supported by the National Science Foundation grants DRL-2025090 and DRL-2321128 (ECR:BCSER). Any opinions, findings, and conclusions expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
