Data Structures & Sociograms
SNA Module 1: Code-Along
Data Intensive Research-Workflow
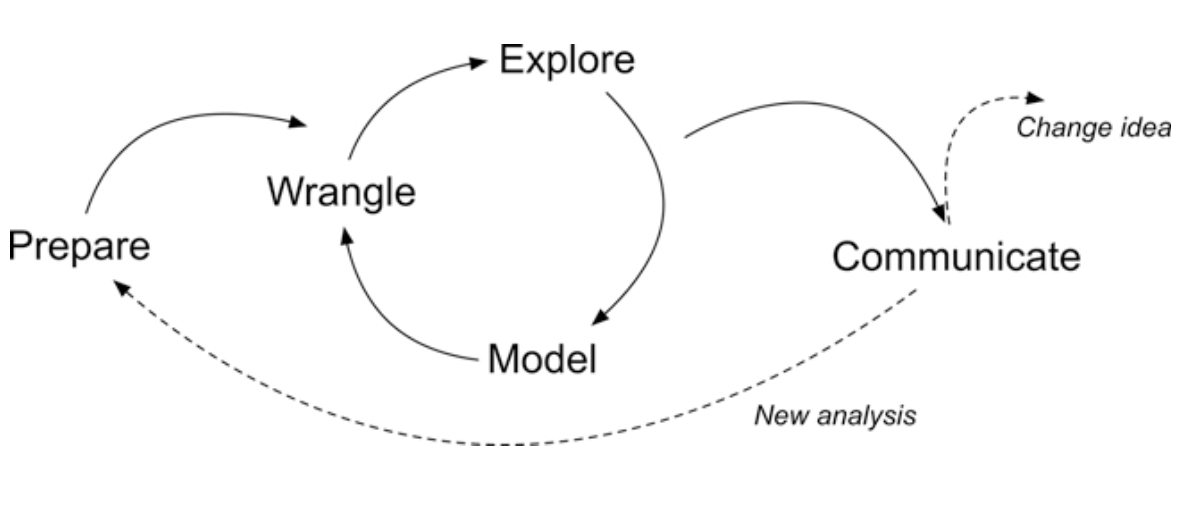
From Learning Analytics Goes to School (Krumm, Means, and Bienkowski 2018)
Guiding Study
Revisiting early work in the field of sociometry, this study by Pittinsky and Carolan (2008) assesses the level of agreement between teacher perceptions and student reports of classroom friendships among middle school students.

The central question guiding this investigation was:
Do student reports agree with teacher perceptions when it comes to classroom friendship ties and with what consequences for commonly used social network measures?
1 teacher, 1 middle school, four classrooms
Students given roster and asked to evaluate relationships with peers
Choices included best friend, friend, know-like, know, know-dislike, strongly dislike, and do not know.
Relations are valued (degrees of friendship, not just yes or no)
Data are directed (friendship nominations were not presumed to be reciprocal).
Teacher’s perceptions and students’ reports were statistically similar, 11–29% of possible ties did not match.
Students reported significantly more reciprocated friendship ties than the teacher perceived.
Observed level of agreement varied across classes and generally increased over time.
Load Packages
Let’s start by creating a new R script and loading the {tidyverse} package which we’ll use to import our network data files:
Note: Tidyverse is actually a collection of R packages that share an underlying design philosophy, grammar, and data structures commonly referred to as “tidy data principles.” LASER uses the {tidyverse} extensively.

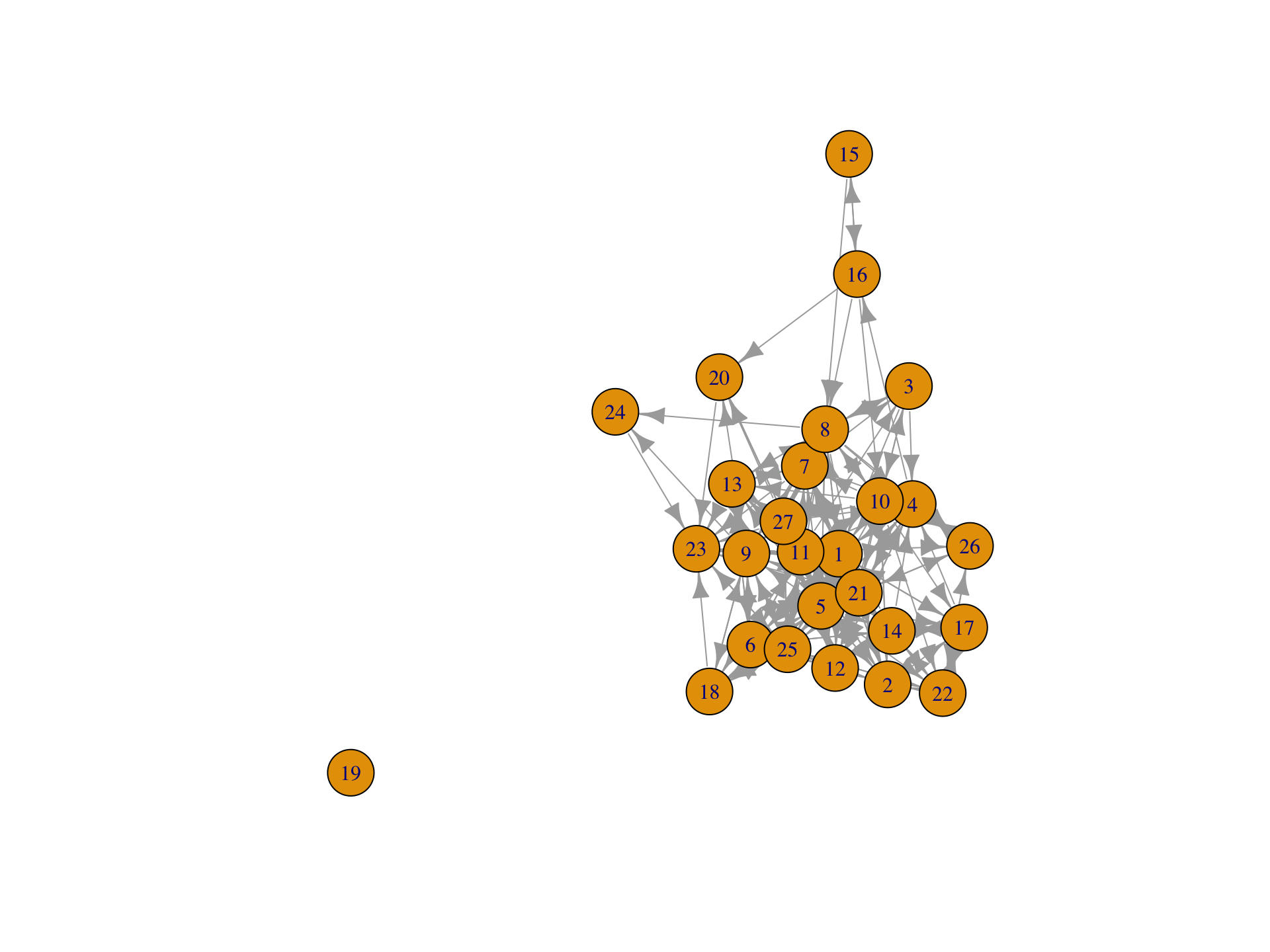
A Simple Sociogram
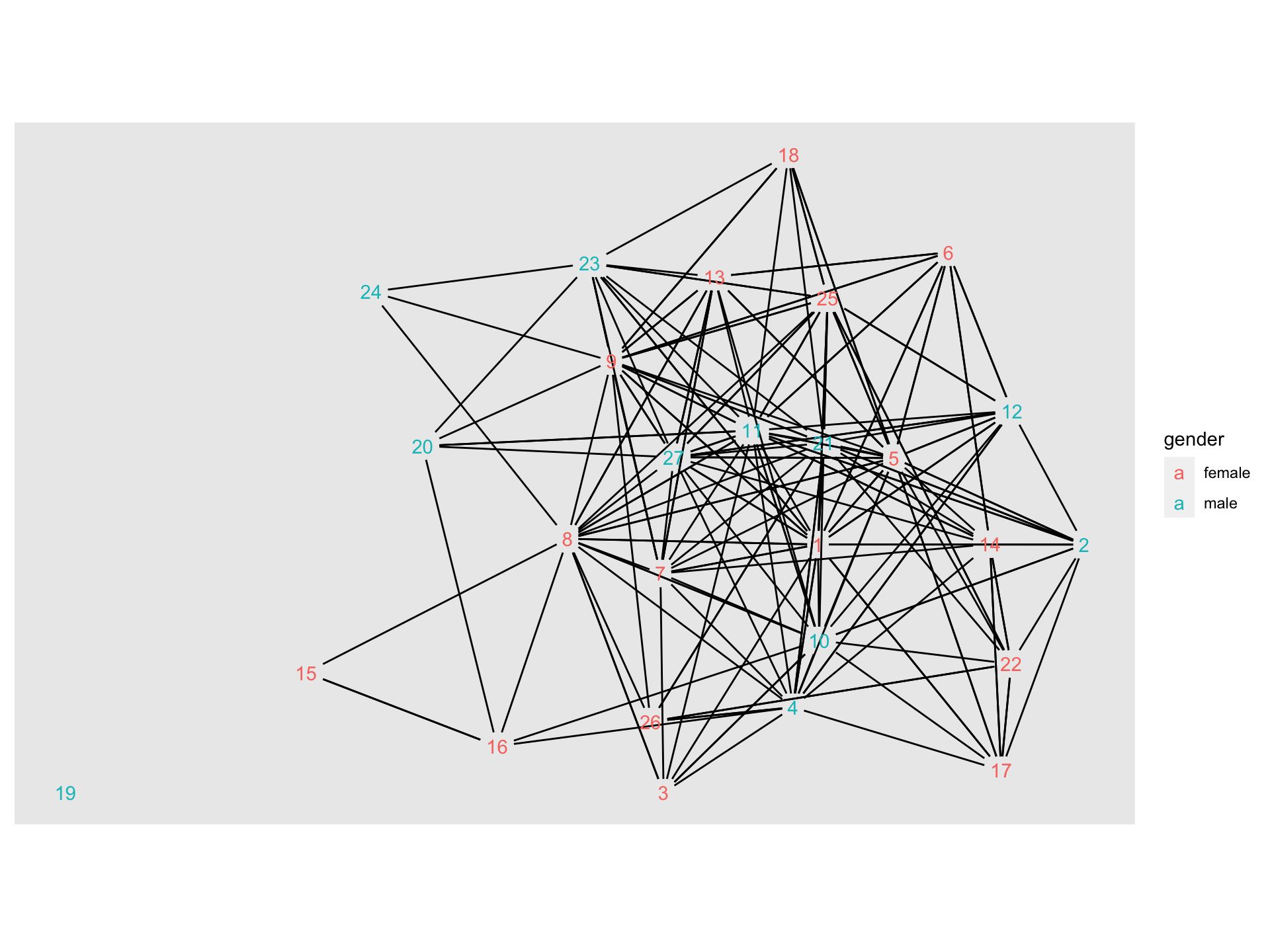
- In what situations might these limited functions be useful?
- When might they inappropriate to use?
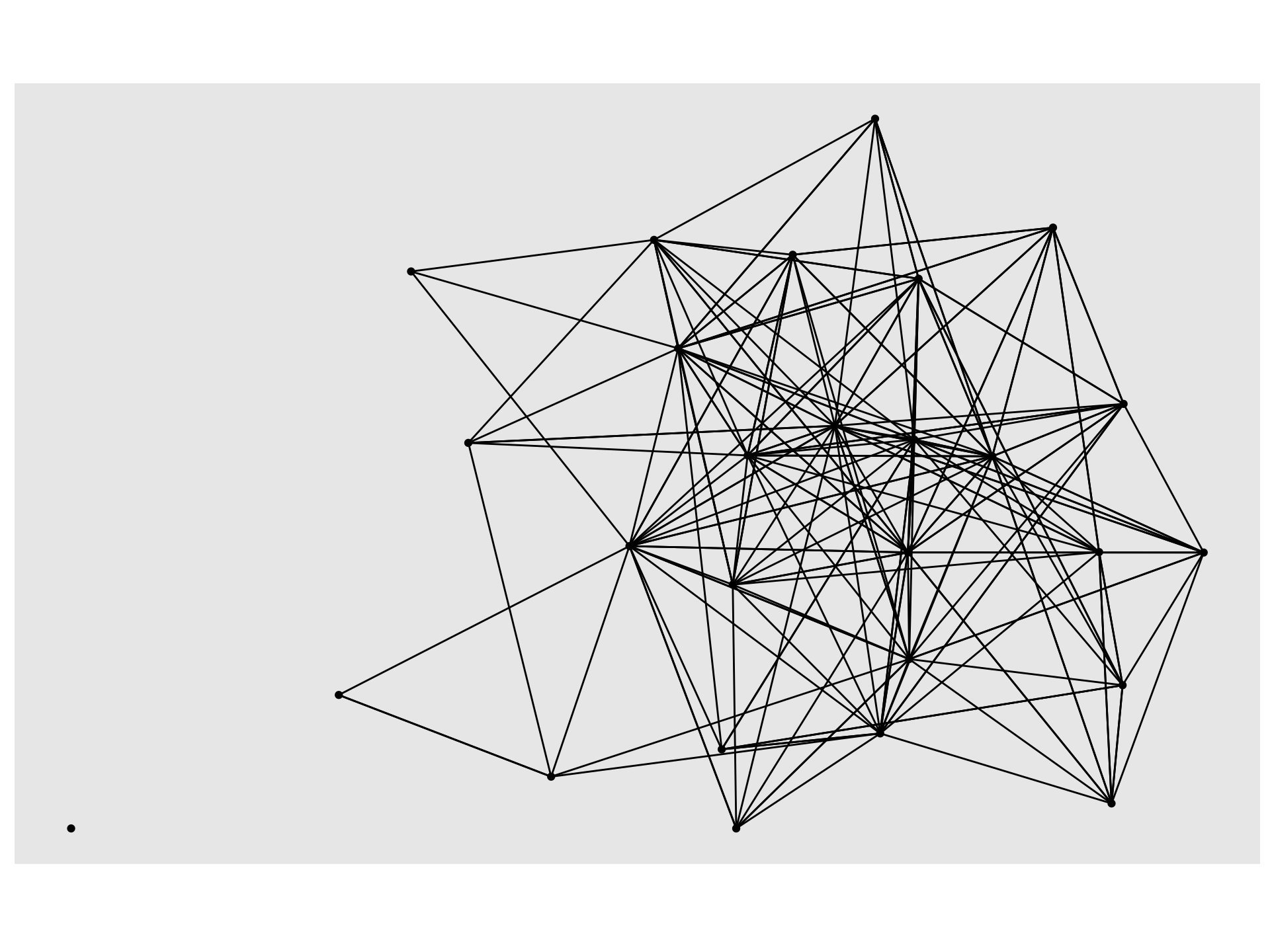
A Sophisticated Sociogram
The ggraph() function is the first function required to build a sociogram. Try running this function on out student_network and see what happens:
This function serves two critical roles:
It takes care of setting up the plot object for the network specified.
It creates the layout based on algorithm provided.

The {ggraph} packages allows for some very fairly sophisticated sociograms…
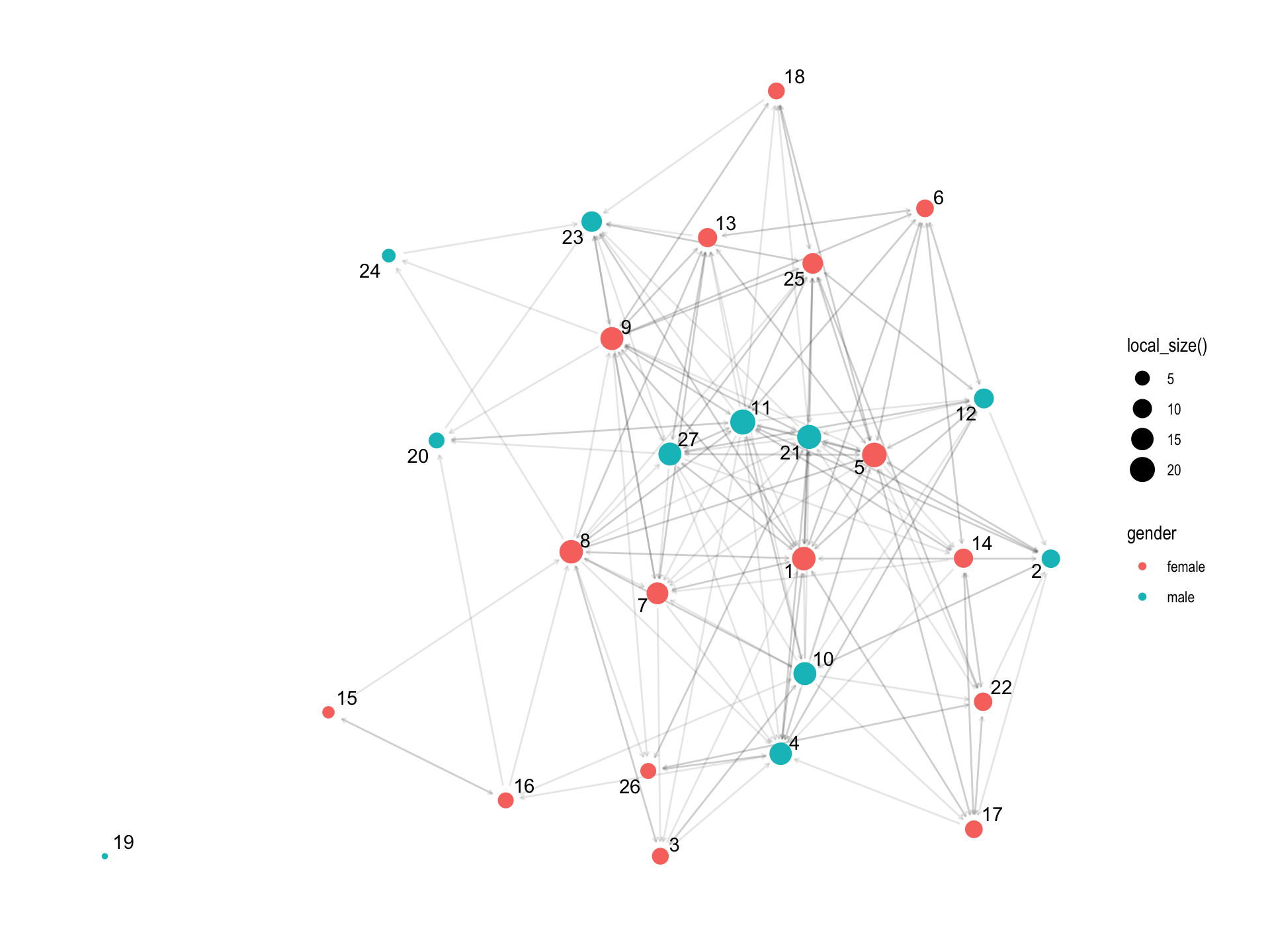
With a fair bit of coding:
Acknowledgements

This work was supported by the National Science Foundation grants DRL-2025090 and DRL-2321128 (ECR:BCSER). Any opinions, findings, and conclusions expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
