# Import pandas for data manipulation and matplotlib for visualization
import pandas as pd
import matplotlib.pyplot as plt
# If not installed, you can run in the terminal:
# python3 -m pip install matplotlib plotly
# python3 -m pip install pandas
# or windows
# py -m pip install matplotlib plotly
# py -m pip install pandasWorkflow & Reproducible Research
Orientation: Code Along
Agenda
Python Code-Along
Data-Intensive Research Workflow
- Prepare
- Wrangle
- Explore
- Model
- Communicate

Explore
Exploratory data analysis in Python involves processes of describing your data numerically or graphically, which often includes:
calculating summary statistics like frequency, means, and standard deviations
visualizing your data through charts and graphs
EDA can be used to help answer research questions, generate new questions about your data, discover relationships between and among variables, and create new variables (i.e., feature engineering) for data modeling.
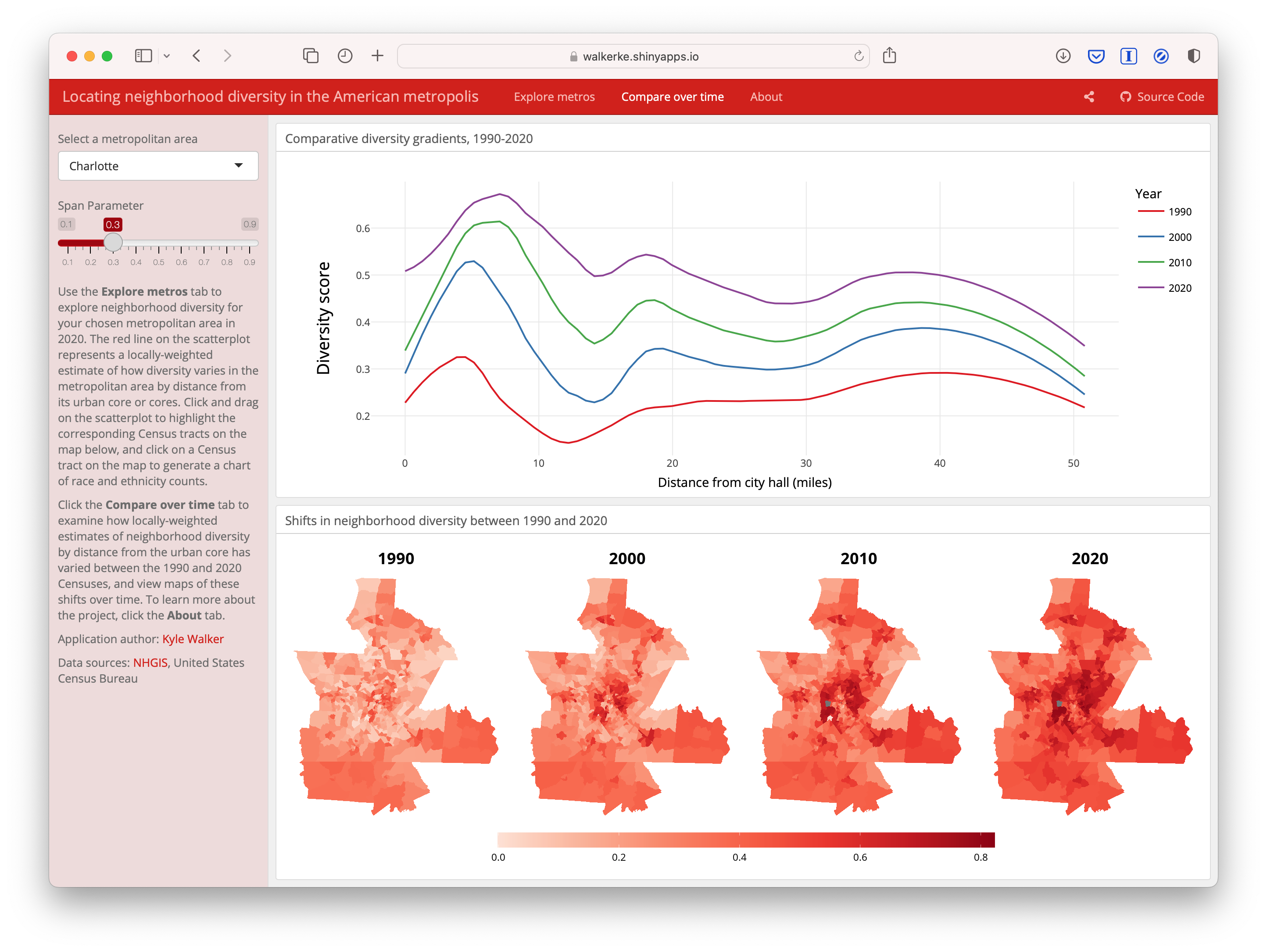
The workflow for making a graph typically involves:
Choosing the type of plot or visualization you want to create.
Using the plotting function directly with your data.
Optionally customizing the plot with titles, labels, and other aesthetic features.
Scatter plots are useful for visualizing the relationship between two continuous variables. Here’s how to create one with seaborn.

Communicate
Krumm et al. (2018) have outlined the following 3-step process for communicating finding with education stakeholders:
Select. Selecting analyses that are most important and useful to an intended audience, as well as selecting a format for displaying that info (e.g. chart, table).
Polish. Refining or polishing data products, by adding or editing titles, labels, and notations and by working with colors and shapes to highlight key points.
Narrate. Writing a narrative pairing a data product with its related research question and describing how best to interpret and use the data product.
 ]
]Acknowledgements

This work was supported by the National Science Foundation grants DRL-2025090 and DRL-2321128 (ECR:BCSER). Any opinions, findings, and conclusions expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
