Prepare and Wrangle
LAW Module 1: A Code Along
Welcome to the LAW Code Along for Module 1
Learning Analytics Workflow (LAW) is designed for those seeking an introductory understanding of learning analytics using basic R programming skills, particularly in the context of STEM education research.
The following Code Along is aimed at preparing you for the first section of the case study.
Reading in Data with readr
fileFile to pathcol_namesUses the first row of raw data available as the column names if TRUE, creates placeholder column names if FALSEnaLooks for text in the data to treat as non-applicable. Can be a list likec("", "na")skipTells the function to “skip” ahead by reading at a given row of data.col_typesCoerces columns to specific types of data. If NULL, the function guesses the type of each column, which is useful but not robust
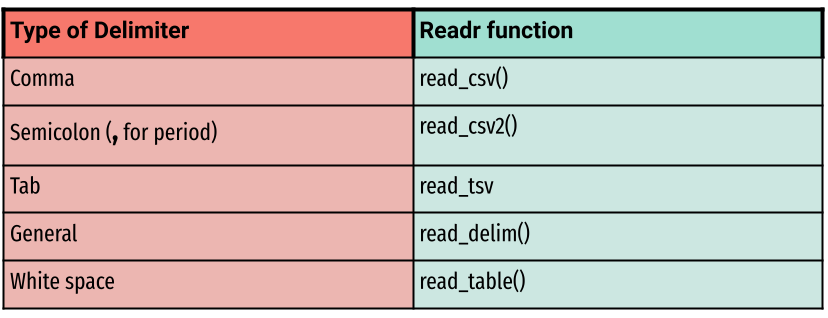
Use
read_csv()to read insci-online.classes.csvThis file is located in your data folder
