# Creating demo data
import pandas as pd
import numpy as np
# Seed for reproducibility
np.random.seed(42)
# Create demo data
demo_data = pd.DataFrame({
'completion_percentage': np.random.uniform(50, 100, 100), # Completion between 50% and 100%
'hours_online': np.random.uniform(1, 50, 100), # Hours online between 1 and 50
'boredom_score': np.random.uniform(1, 5, 100) # Boredom score between 1 and 5
})Model
Foundations Python Module 3: Code-A-long
Steps in the Modeling Process

Multiple regression
Instructions:
Clean the data using the
dropna()functionCreate a linear regression model with
hours_onlineandboredom_scoreas the independent variable andcompletion_percentageas the dependent variable.Fit the model and inspect the summary.
#install libraries
import seaborn as sns #seaborn
import matplotlib.pyplot as plt #matplot
# Step 1: Drop rows with missing values in any of the selected columns
cleaned_data = demo_data.dropna()
# Step 1a: Verify that there are no missing values in cleaned_data
print(cleaned_data.isna().sum())
# Steps 2, add independent and dependent variables to X and y
X = cleaned_data[['hours_online', 'boredom_score']] # independent variables
y = cleaned_data['completion_percentage'] # dependent variable
# Adding a constant to the model (for the intercept)
X = sm.add_constant(X)
# Steps 4 and 5 to Fit the model
model = sm.OLS(y, X, missing='drop').fit()
# Output the summary of the model
print(model.summary())completion_percentage 0
hours_online 0
boredom_score 0
dtype: int64
OLS Regression Results
=================================================================================
Dep. Variable: completion_percentage R-squared: 0.009
Model: OLS Adj. R-squared: -0.019
Method: Least Squares F-statistic: 0.3072
Date: Mon, 22 Jul 2024 Prob (F-statistic): 0.736
Time: 21:01:38 Log-Likelihood: -302.45
No. Observations: 74 AIC: 610.9
Df Residuals: 71 BIC: 617.8
Df Model: 2
Covariance Type: nonrobust
=================================================================================
coef std err t P>|t| [0.025 0.975]
---------------------------------------------------------------------------------
const 78.1010 6.191 12.615 0.000 65.756 90.446
hours_online -0.0954 0.123 -0.778 0.439 -0.340 0.149
boredom_score -0.3567 1.484 -0.240 0.811 -3.315 2.602
==============================================================================
Omnibus: 28.689 Durbin-Watson: 1.998
Prob(Omnibus): 0.000 Jarque-Bera (JB): 4.959
Skew: 0.027 Prob(JB): 0.0838
Kurtosis: 1.733 Cond. No. 106.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.👉 Your Turn ⤵
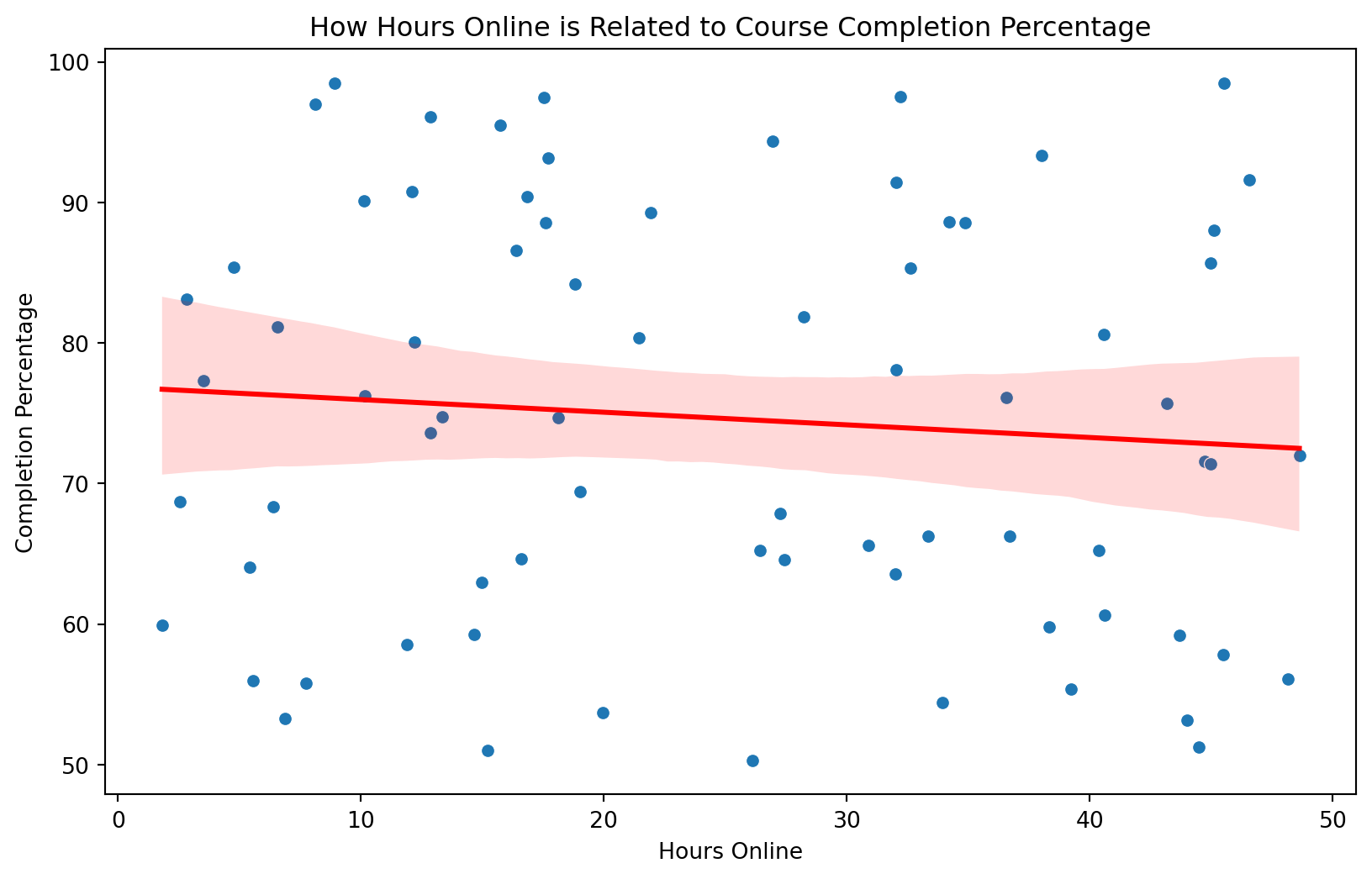
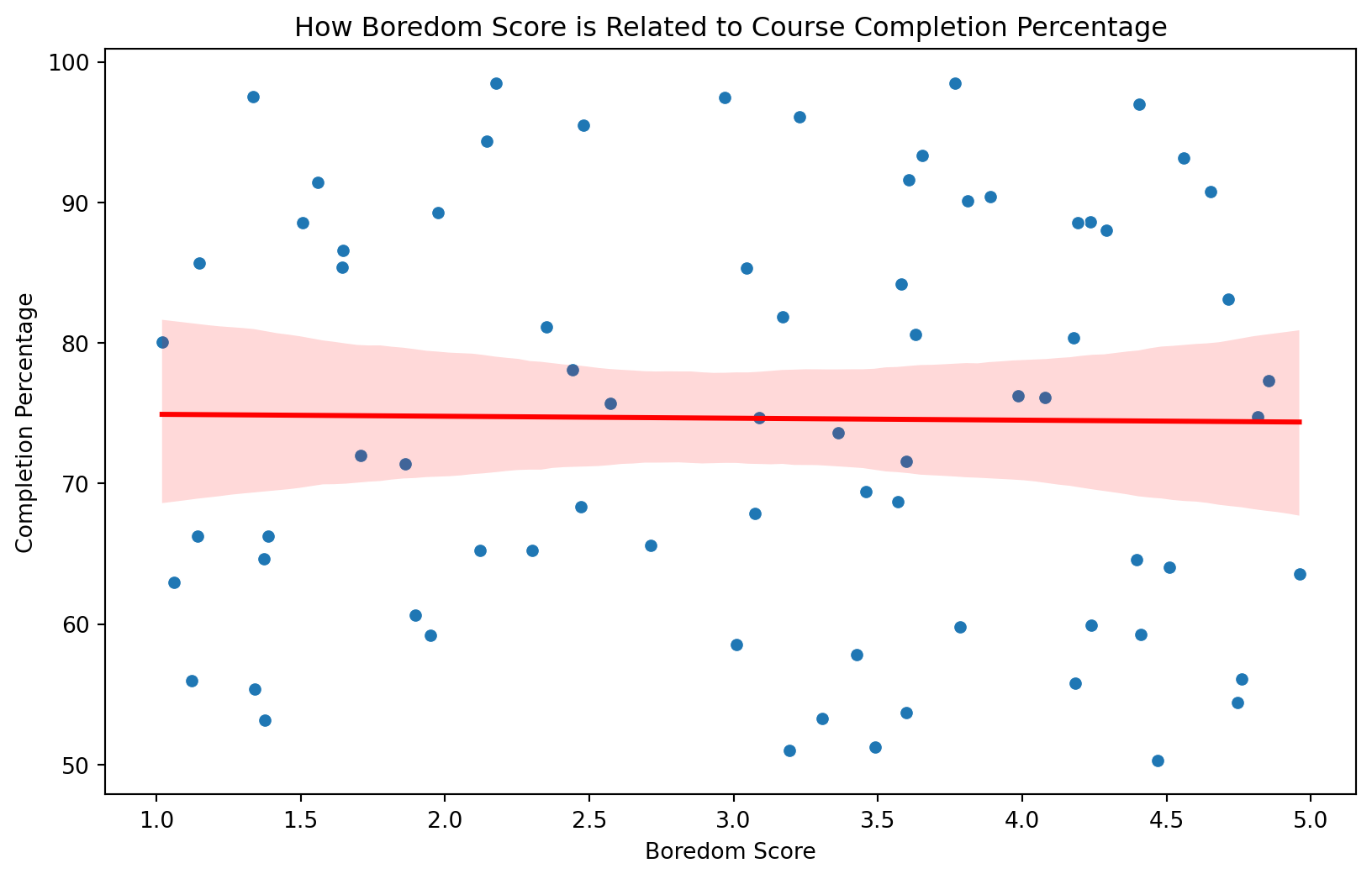
Vizualise the model with a scatter plot and regression line
To see the code check out the slides.
What’s next?
- Complete the
Modelparts of the Case Study. - Complete the Badge requirement document Foundations badge - Data Sources
- Do required readings for the next Foundations Module 4.
