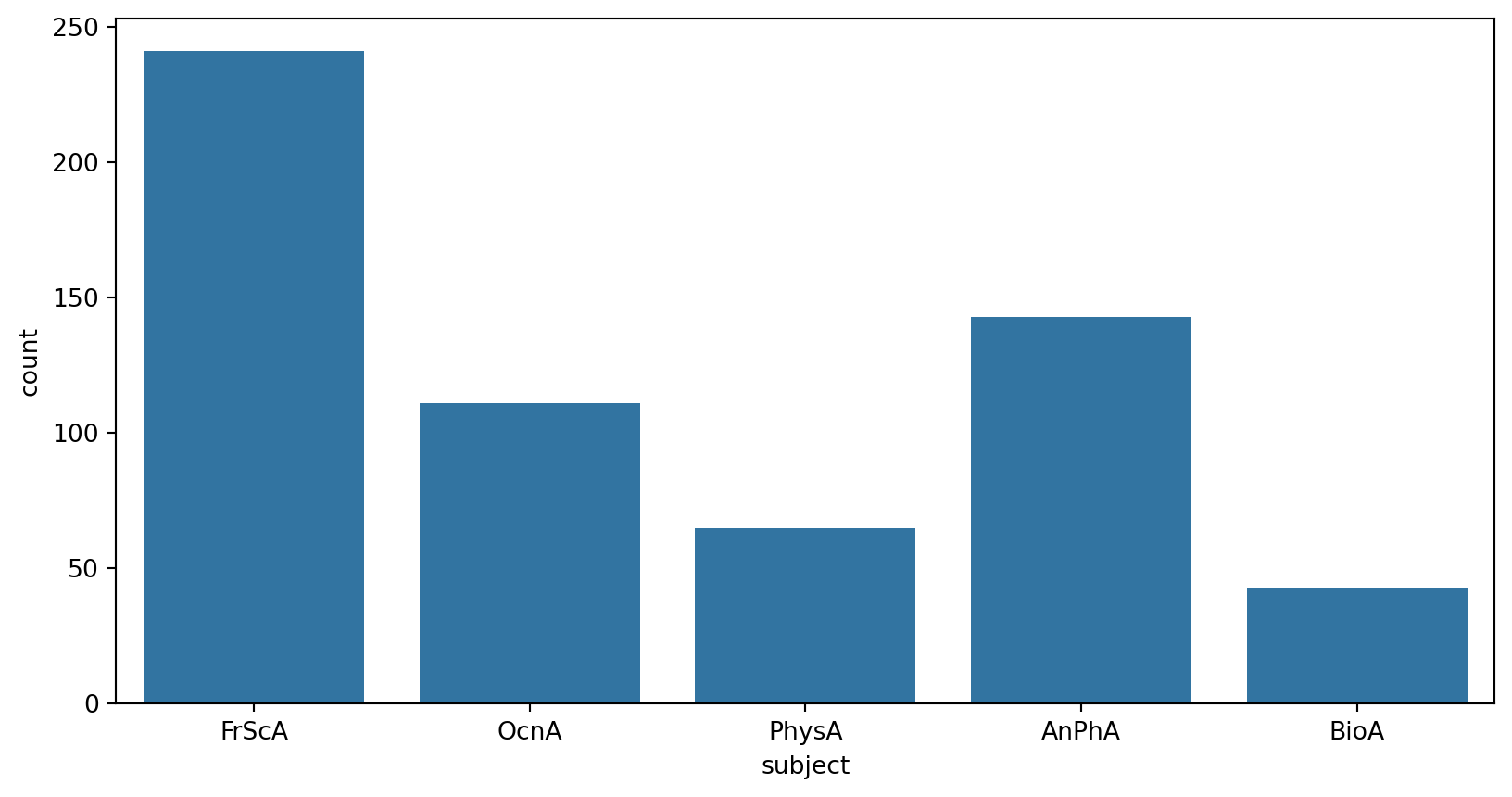
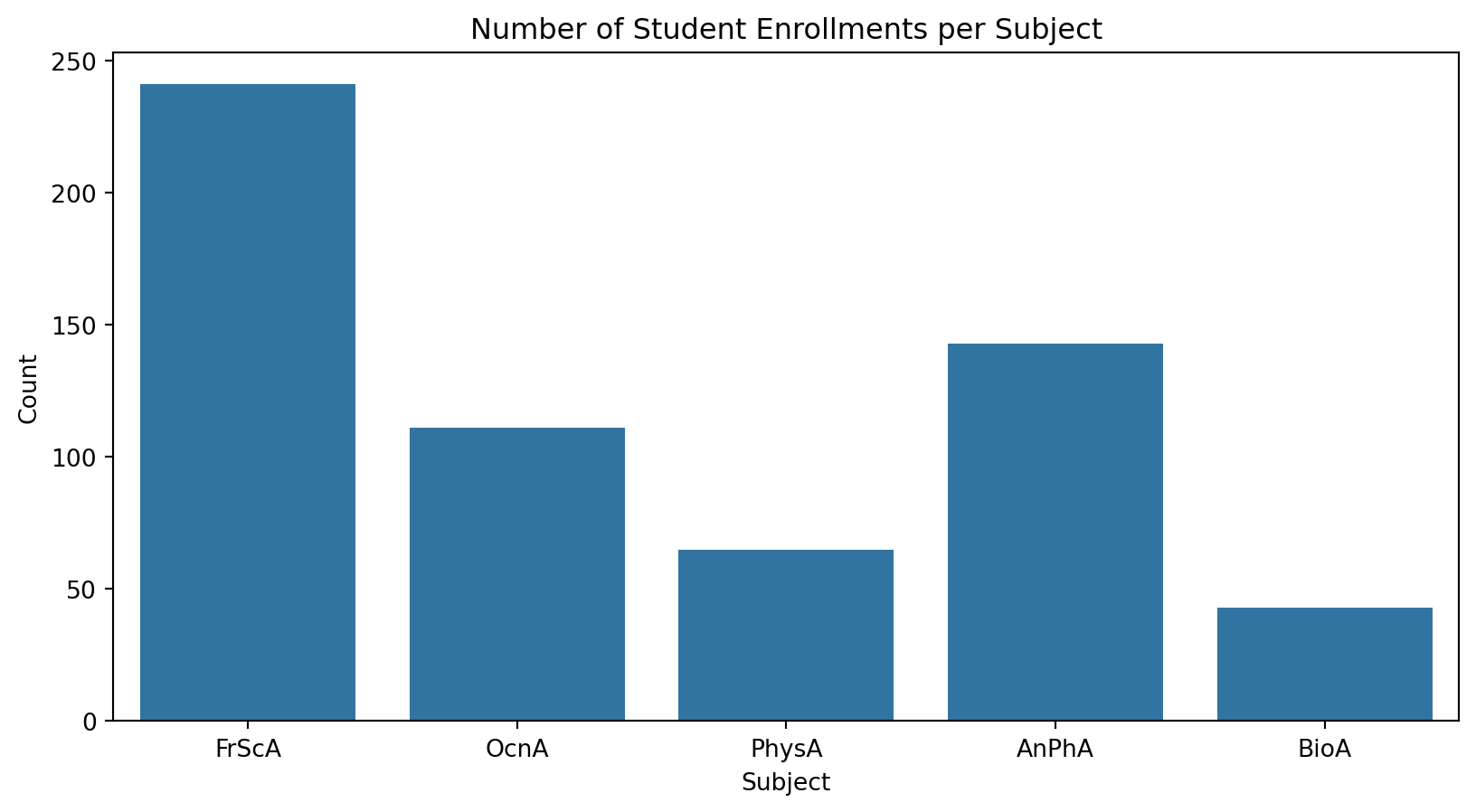
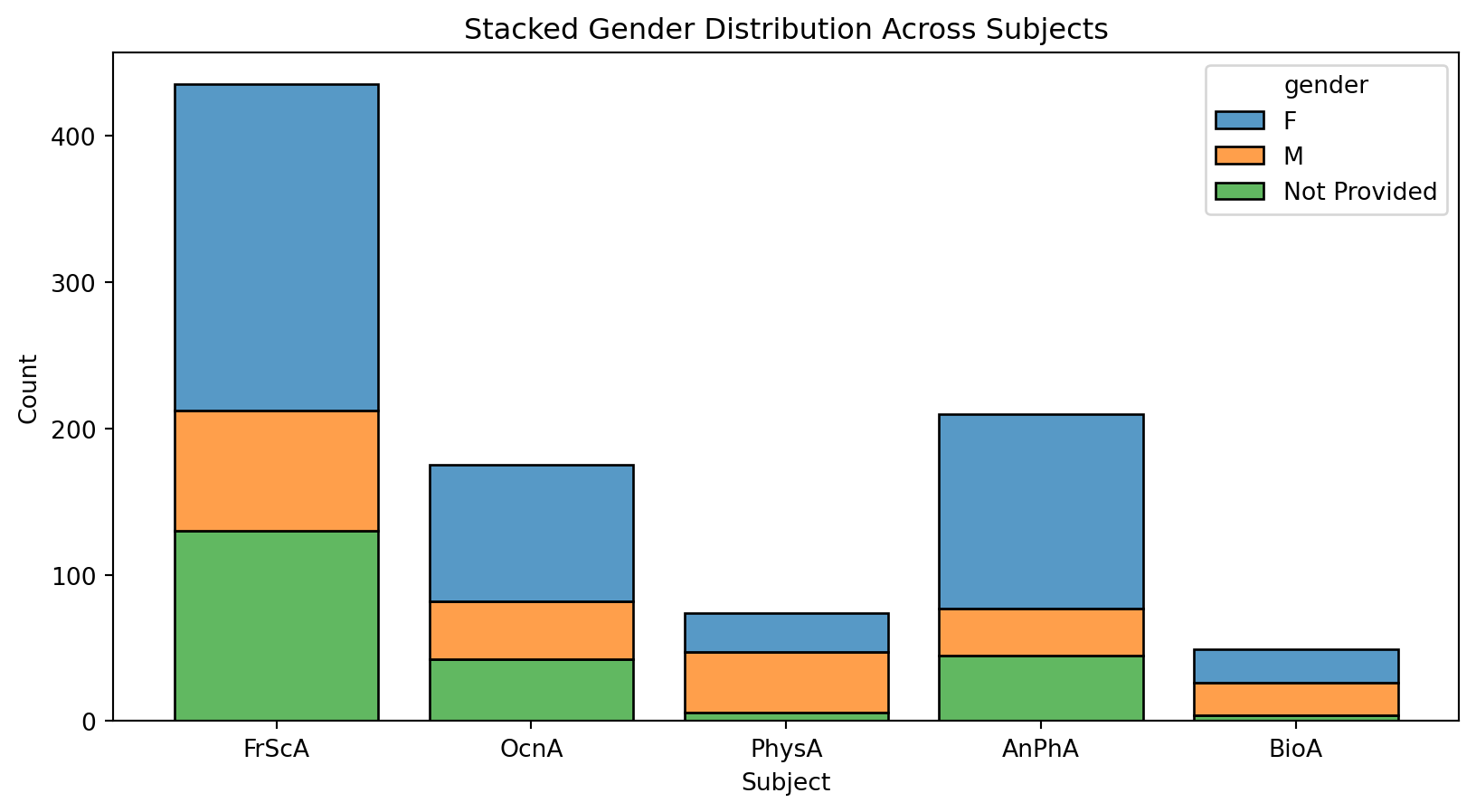
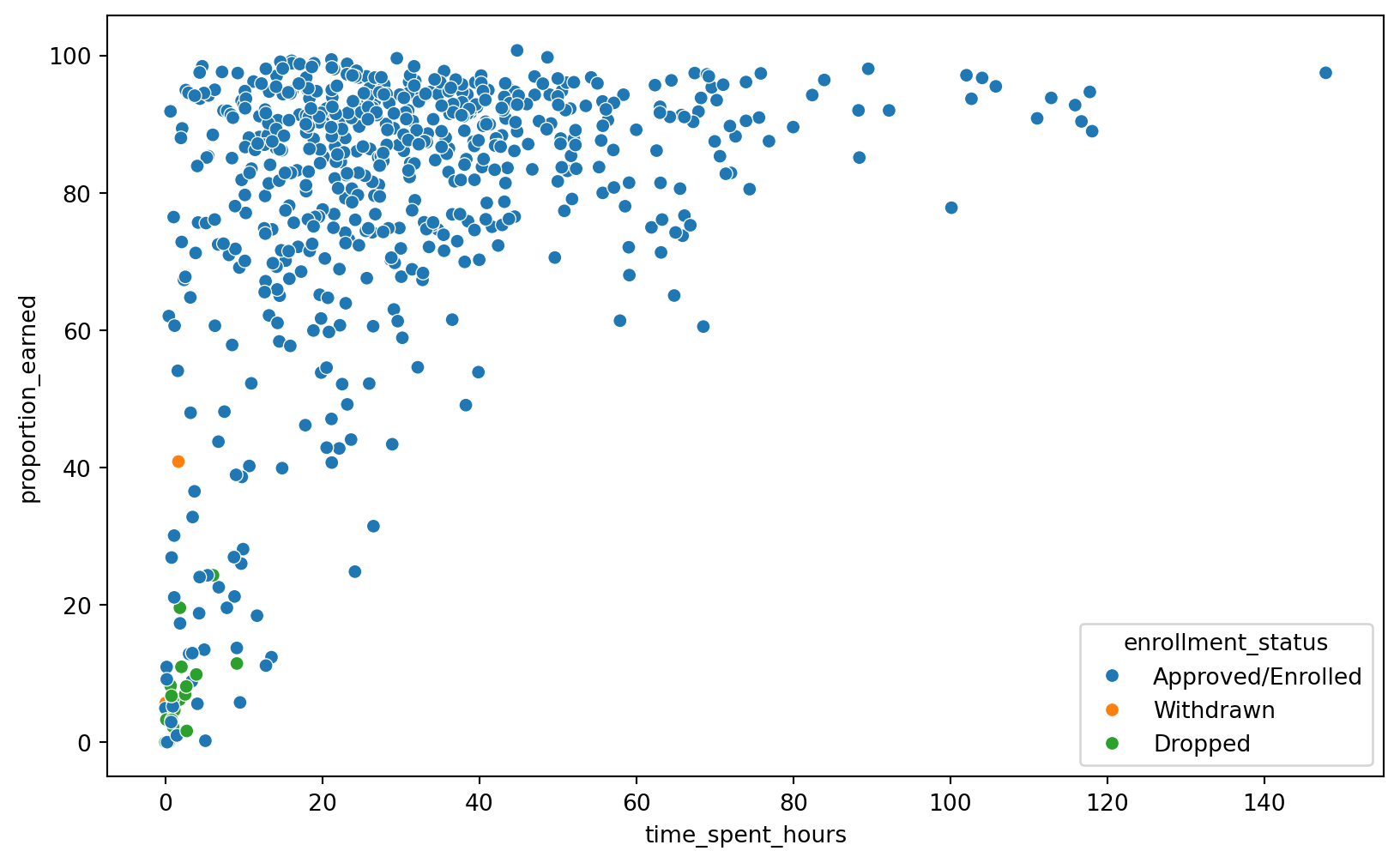
import pandas as pd
import numpy as np
# read and load `sci-online-classes.csv` from data folder
time_spent = pd.read_csv("data/sci-online-classes.csv")
# Find cells with missing values
null_data = time_spent.isnull()
# Calculate the number of missing values
missing_count = null_data.sum()
print(missing_count)student_id 0
course_id 0
total_points_possible 0
total_points_earned 0
percentage_earned 0
subject 0
semester 0
section 0
Gradebook_Item 0
Grade_Category 603
FinalGradeCEMS 30
Points_Possible 0
Points_Earned 92
Gender 0
q1 123
q2 126
q3 123
q4 125
q5 127
q6 127
q7 129
q8 129
q9 129
q10 129
TimeSpent 5
TimeSpent_hours 5
TimeSpent_std 5
int 76
pc 75
uv 75
dtype: int64