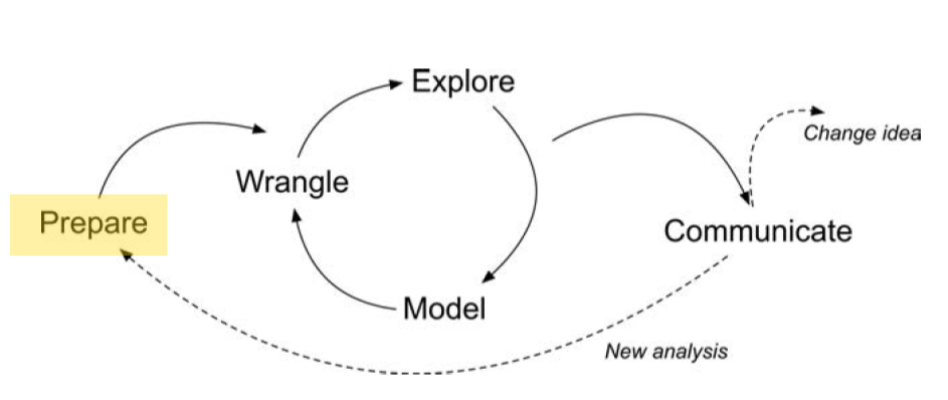
Prepare and Wrangle
Foundations Python Module 1: Code-A-long
Welcome to Foundations code along for Module 1
Foundations of Learning Analyticsare designed for those seeking an introductory understanding of learning analytics and either basic R programming skills or basic Python skills, particularly in the context of STEM education research. The following code along is aimed at preparing you for the first section of the case study.
Install Packages
- First time using a package
- Do this ONLY ONCE in the “terminal”

Load Packages
Let’s start by creating a new Python script and loading some essential packages introduced in LA Workflows:


NumPy is a Python package for scientific computing with Python. It is used for various types of data manipulation and mathematical operations, particularly when working with large datasets or complex mathematical computations.
Use your Python script to import the {numpy} package as np.
If this is your first time you will need to install the package in the terminal:
MAC/LINUX: $ python3 -m pip install numpy
Windows: $ py -m pip install numpy
Reading in Data



Joining data

Let’s create Mock Data Generation
# Create mock data
import pandas as pd
students = pd.DataFrame({
'student_id': [1, 2, 3, 4],
'name': ['Alice', 'Bob', 'Charlie', 'David'],
'major': ['Math', 'Physics', 'Biology', 'Computer Science']
})
students| student_id | name | major | |
|---|---|---|---|
| 0 | 1 | Alice | Math |
| 1 | 2 | Bob | Physics |
| 2 | 3 | Charlie | Biology |
| 3 | 4 | David | Computer Science |
# Left join: Returns all rows from the left table, and the matched rows from the right table. If there is no match, the result is NA.
left_join_result = pd.merge(students, scores, on='student_id', how='left')
left_join_result| student_id | name | major | score | |
|---|---|---|---|---|
| 0 | 1 | Alice | Math | 85.0 |
| 1 | 2 | Bob | Physics | 90.0 |
| 2 | 3 | Charlie | Biology | 75.0 |
| 3 | 4 | David | Computer Science | NaN |
# Right join: Returns all rows from the right table, and the matched rows from the left table. If there is no match, the result is NA.
right_join_result = pd.merge(students, scores, on='student_id', how='right')
right_join_result| student_id | name | major | score | |
|---|---|---|---|---|
| 0 | 1 | Alice | Math | 85 |
| 1 | 2 | Bob | Physics | 90 |
| 2 | 3 | Charlie | Biology | 75 |
| 3 | 5 | NaN | NaN | 80 |
# Full join: Returns all rows from both tables. If there is no match, the result is NA for the missing values.
full_join_result = pd.merge(students, scores, on='student_id', how='outer')
full_join_result| student_id | name | major | score | |
|---|---|---|---|---|
| 0 | 1 | Alice | Math | 85.0 |
| 1 | 2 | Bob | Physics | 90.0 |
| 2 | 3 | Charlie | Biology | 75.0 |
| 3 | 4 | David | Computer Science | NaN |
| 4 | 5 | NaN | NaN | 80.0 |
What’s next?
- Complete the
PrepareandWrangleparts of the Case Study. - Complete the Badge requirement document Foundations badge - Data Sources
- Do required readings for the next Foundations Module 2.
