Intro to Quantitative Enthnography
Text Mining Module 4: A Conceptual Overview
Communicate
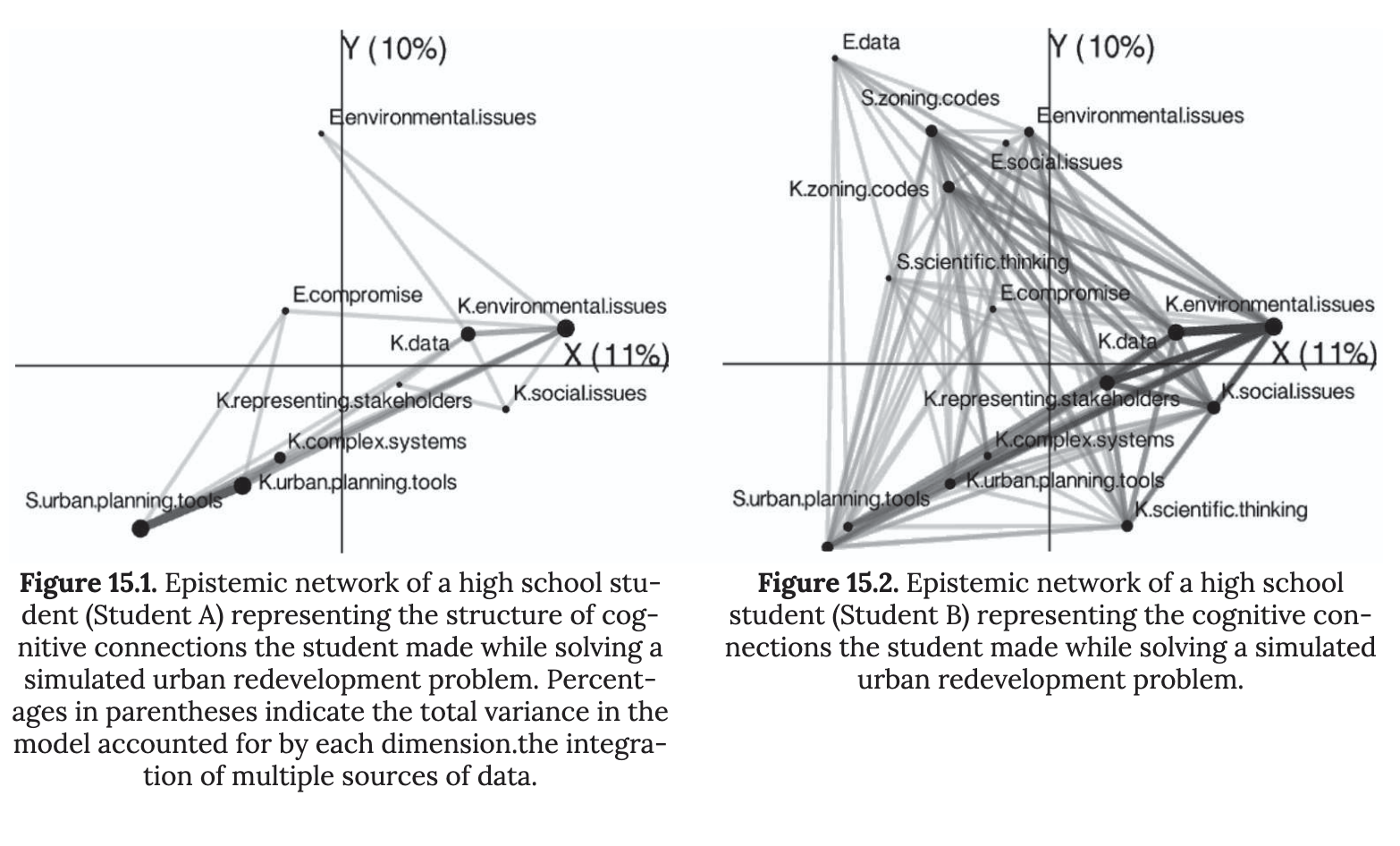
Using ENA with R
- R is able to conduct ENA through the
rENApackage!
Acknowledgements

This work was supported by the National Science Foundation grants DRL-2025090 and DRL-2321128 (ECR:BCSER). Any opinions, findings, and conclusions expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
