library(academictwitteR)
library(tidyverse)
ccss_tweets_2021 <-
get_all_tweets('(#commoncore OR "common core") -is:retweet lang:en',
"2021-01-01T00:00:00Z",
"2021-05-31T00:00:00Z",
bearer_token,
data_path = "ccss-data/",
bind_tweets = FALSE)
ccss_tweets <- bind_tweet_jsons(data_path = "ccss-data/") |>
select(text,
created_at,
author_id,
id,
conversation_id,
source,
possibly_sensitive,
in_reply_to_user_id)
write_csv(ccss_tweets, "data/ccss-tweets.csv")Twitter Sentiment Towards State Standards
TM Module 2: Case Study Key
0. INTRODUCTION
Data sources such as digital learning environments and administrative data systems, as well as data produced by social media websites and the mass digitization of academic and practitioner publications, hold enormous potential to address a range of pressing problems in education, but collecting and analyzing text-based data also presents unique challenges. This week, our case study is guided by my colleague Josh Rosenberg’s study, Understanding Public Sentiment about Educational Reforms: The Next Generation Science Standards on Twitter. We will focus on conducting a very simplistic “replication study” by comparing the sentiment of tweets about the Next Generation Science Standards (NGSS) and Common Core State Standards (CCSS) in order to better understand public reaction to these two curriculum reform efforts.
Case Study Focus
For Module 2, our focus will be using data that was collected using a now sadly depricated Twitter API and using sentiment lexicons to help gauge public opinion about those topics or tweets. The following diagram from Silge & Robinson Silge and Robinson (2017) nicely illustrates the process of using text mining {tidverse} functions to analyze the sentiment of text:

For Module 2, our case study will cover the following topics:
- Prepare: Prior to analysis, it’s critical to understand the context and data sources you’re working with so you can formulate useful and answerable questions. We’ll take a quick look at Dr. Rosenberg’s study as how data through Twitter’s now deprecated API.
- Wrangle: In section 2 we revisit tidying and tokenizing text from Module 1 and learn some new functions for appending sentiment scores to our tweets using the AFFIN, bing, and nrc sentiment lexicons.
- Explore: In section 3, we use simple summary statistics and basic data visualization to compare sentiment between NGSS and CCSS tweets.
- Model: We explore the {vader} package to model the sentiment of tweets, as well as examine a mixed-effects model used by Rosenberg et al. to analyze the sentiment of tweets.
- Communicate: Finally, I’ll demonstrated a simple data product for communicating findings from our analysis.
1. PREPARE
To help us better understand the context, questions, and data sources we’ll be using in Module 2, this section will focus on the following topics:
- Context. We take a quick look at the Rosenberg et al. Rosenberg et al. (2020) article, Understanding Public Sentiment about Educational Reforms: The Next Generation Science Standards on Twitter, including the purpose of the study, questions explored, and findings.
- Questions. We’ll formulate some basic questions that we’ll use to guide our analysis, attempting to replicate some of the findings by Rosenberg et al.
- Twitter API. We describe the process used to pull data from old Twitter API.
1a. Reseach Context
Twitter and the Next Generation Science Standards

Abstract
While the Next Generation Science Standards (NGSS) are a long-standing and widespread standards-based educational reform effort, they have received less public attention, and no studies have explored the sentiment of the views of multiple stakeholders toward them. To establish how public sentiment about this reform might be similar to or different from past efforts, we applied a suite of data science techniques to posts about the standards on Twitter from 2010-2020 (N = 571,378) from 87,719 users. Applying data science techniques to identify teachers and to estimate tweet sentiment, we found that the public sentiment towards the NGSS is overwhelmingly positive—33 times more so than for the CCSS. Mixed effects models indicated that sentiment became more positive over time and that teachers, in particular, showed a more positive sentiment towards the NGSS. We discuss implications for educational reform efforts and the use of data science methods for understanding their implementation.
Data Sources
Similar to data we’ll be using for this case study, Rosenberg et al. used publicly accessible data from Twitter collected using the Full-Archive Twitter API and the {rtweet} package in R. Specifically, the authors accessed tweets and user information from the hashtag-based #NGSSchat online community, all tweets that included any of the following phrases, with “/” indicating an additional phrase featuring the respective plural form: “ngss”, “next generation science standard/s”, “next gen science standard/s”.
Data used in this case study was obtained prior to Twitter’s transition to X, and used the now retired {academictwitter} package along with an Academic Research developer account, which is sadly no longer accessible. The Twitter API v2 endpoints allowed researchers to access the full twitter archive, unlike a standard developer account. Data includes all tweets from January through May of 2020 and included the following terms: #ccss, common core, #ngsschat, ngss.
Below is an example of the code used to retrieve data for this case study. This code is set not to execute and will NOT run, but it does illustrate the search query used, variables selected, and time frame.
Analysis
The authors determined Tweet sentiment using the Java version of SentiStrength to assign tweets to two 5-point scales of sentiment, one for positivity and one for negativity, because SentiStrength is a validated measure for sentiment in short informal texts (Thelwall et al., 2011). In addition, they used this tool because Wang and Fikis (2019) used it to explore the sentiment of CCSS-related posts.
We’ll be using the AFINN sentiment lexicon which also assigns words in a tweet to two 5-point scales, in addition to exploring some other sentiment lexicons to see if they produce similar results. We will use a similar approach to label tweets as positive, negative, or neutral using the {Vader} package which greatly simplifies this process.
Note that the authors also used the lme4 package in R to run a mixed effects model to determine if sentiment changes over time and differs between teachers and non-teacher. We will not attempt replicated that aspect of the analysis, but if you are interested in a guided case study of how modeling can be used to understand changes in Twitter word use, see Chapter 7 of Text Mining with R.
❓Questions
Take a quick look at the article by Rosenberg et al. and write below a two key findings from their analysis as well as a limitation of this study:
- KEY FINDING 1
- KEY FINDING 2
- STUDY LIMITATION
1b. Guiding Questions
The purpose of this study was to understand the nature of the public sentiment expressed toward the NGSS, as well as sources of variation (including the year of the post and the professional role of users, among others) for sentiment. The following two research questions guided this study:
What public sentiment is expressed on the social media platform Twitter toward the NGSS?
What factors explain variation in this public sentiment?
For this case study, we’ll use a similar approach used by the authors to guage public sentiment around the NGSS, by comparing how much more positive or negative NGSS tweets are relative to CSSS tweets.
Our (very) specific questions of interest for this case study are:
- What is the public sentiment expressed toward the NGSS?
- How does sentiment for NGSS compare to sentiment for CCSS?
And just to reiterate from Module 1, one overarching question we’ll explore throughout the Text Mining modules, and that Silge and Robinson (2018) identify as a central question to text mining and natural language processing, is:
How do we to quantify what a document or collection of documents is about?
1c. Load Libraries
As highlighted in Chapter 6 of Data Science in Education Using R (DSIEUR), packages are shareable collections of R code that contain functions, data, and documentation. Sometimes refered to as libraries, these packages:
increase the functionality of R by providing access to additional functions to suit a variety of needs. While it is entirely possible to do your work in R without packages, it’s not recommend. There are a wealth of packages available that reduce the learning curve the time spent on analytical projects.
Run the code chunk below to load packages that were introduced in Module 1:
library(tidyverse)
library(writexl)
library(readxl)
library(tidytext)The scales Package 📦

The {scales} package in R provides tools for working with numeric data, especially in data visualization contexts. It includes functions to:
Format axis labels (e.g., add thousands separators, percentages, currency symbols).
Rescale numeric data to a specific range or transform data (log, sqrt, etc.).
Define and manipulate color palettes and gradients.
Integrate smoothly with packages like ggplot2 to enhance data visualization.
Run the following code chunk to load the {scales} package:
library(scales)The textdata Package 📦

The {textdata} package integrates nicely with the {tidytext} package and provides streamlined access to various text-based datasets, which are commonly used for text mining, natural language processing, and sentiment analysis. Some examples of datasets accessible via textdata include sentiment lexicons (e.g., sentiment lexicons like AFINN, NRC, or Bing), specialized word lists, and linguistic resources.
Run the following code chunk to load the {textdata} package:
library(textdata)The vader Package 📦

The {vader} package is for the Valence Aware Dictionary for sEntiment Reasoning (VADER), a rule-based model for general sentiment analysis of social media text and specifically attuned to measuring sentiment in microblog-like contexts.
To learn more about the {vader} package and its development, take a look at the article by Hutto and Gilbert (2014), VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text.
👉 Your Turn ⤵
Use the code chunk below to load the VADER library:
# YOUR CODE HERE
Note
The {vader} package can take quite some time to run on a large datasets like the one we’ll be working with, so in our Model section we will examine just a small(ish) subset of tweets.
2. WRANGLE
In general, data wrangling involves some combination of cleaning, reshaping, transforming, and merging data (Wickham & Grolemund, 2017). The importance of data wrangling is difficult to overstate, as it involves the initial steps of going from raw data to a dataset that can be explored and modeled (Krumm et al, 2018).
- Import Data. In this section, we’ll import our CCSS and NGSS tweets and make our first assessment of their sentiment.
- Tidy Tweets. We revisit the
tidytextpackage to both “tidy” and tokenize our tweets in order to create our data frame for analysis. - Get Sentiments. We conclude our data wrangling by introducing sentiment lexicons and the
inner_join()function for appending sentiment values to our data frame.
2a. Import Tweets from CSV
Data for this case study includes all tweets from January through May of 2020 and includes the following terms: #ccss, common core, #ngsschat, ngss. Since we’ll be working with some computational intensive functions later in this case study that can take some time to run, I restricted the time frame for my search to only a handful of month. Even so, we’ll be working with nearly 30,000 tweets and nearly 1,000,000 words for our analysis!
Let’s use the by now familiar read_csv() function to import our ccss_tweets.csv file saved in our data folder:
ccss_tweets <- read_csv("data/ccss-tweets.csv",
col_types = cols(author_id = col_character(),
id = col_character(),
conversation_id = col_character(),
in_reply_to_user_id = col_character()
)
)
ccss_tweetsNote the addition of the col_types = argument for changing some of the column types to character strings because the numbers for those particular columns actually indicate identifiers for authors and tweets:
author_id= the author of the tweetid= the unique id for each tweetconverastion_id= the unique id for each conversation threadin_reply_to_user_id= the author of the tweet being replied to
👉 Your Turn ⤵
Complete the following code chunk to import the NGSS tweets located in the same data folder as our common core tweets and named ngss-tweets.csv. By default, R will treat numerical IDs in our dataset as numeric values but we will need to convert these to characters like demonstrated above for the purpose of analysis. Also, feel free to repurpose the code from above.
ngss_tweets <- # YOUR CODE HERE
ngss_tweetsImporting data and dealing with data types can be a bit tricky, especially for beginners. Recall from previous case studies that RStudio has an “Import Dataset” feature in the Environment Pane that can help you use the {readr} package and associated functions to greatly facilitate this process. If you get stuck, you can copy the code generated in the lower right hand corner of the Import Dataset window.
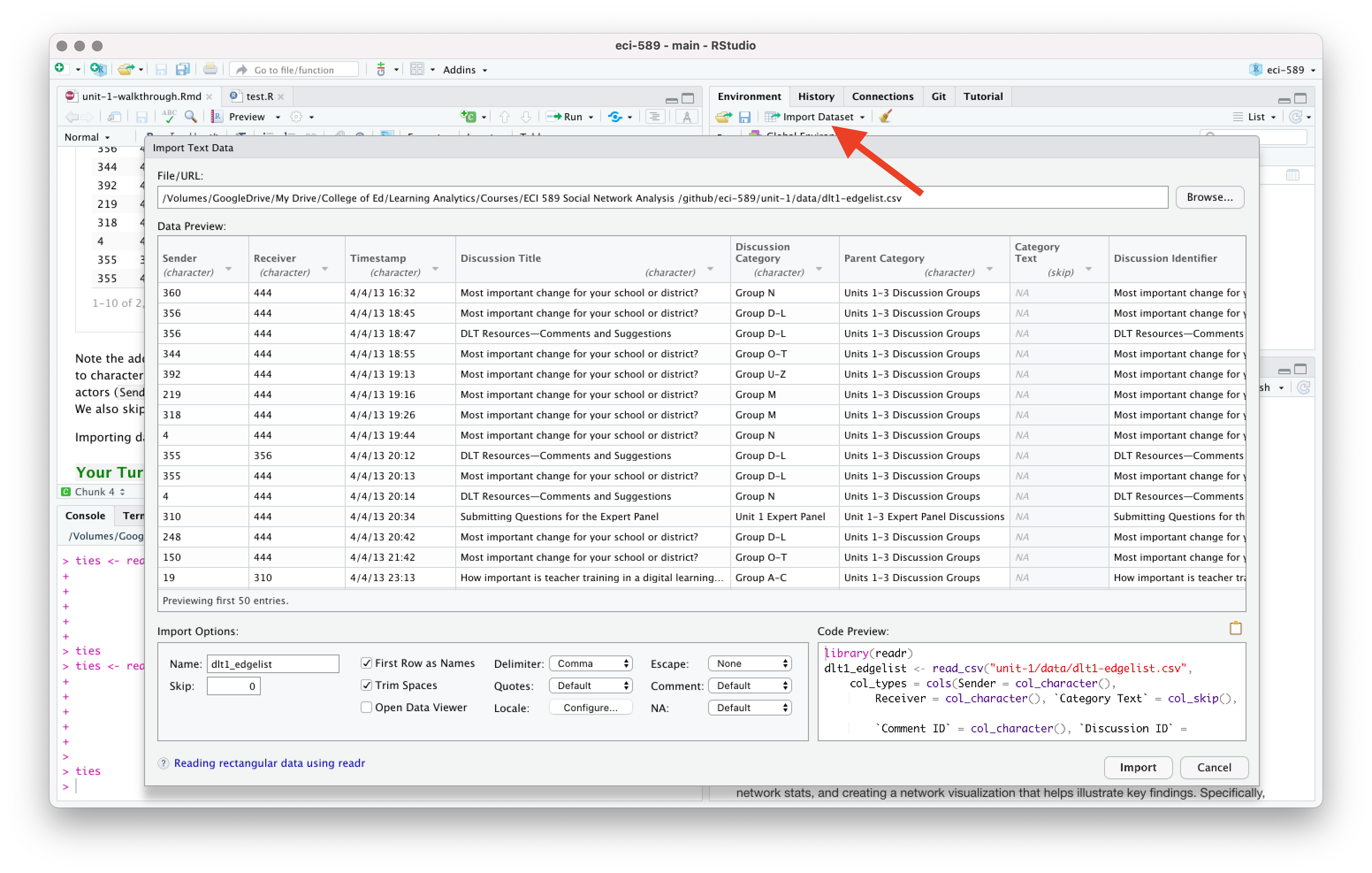
Now use the following code chunk to inspect the head() of each data frame and answer the questions that follow:
head(ngss_tweets)
head(ccss_tweets)Wow, so much for a family friendly case study! Based on this very limited sample, which set of standards do you think Twitter users are more negative about?
- YOUR RESPONSE HERE
Let’s take a slightly larger sample of the CCSS tweets:
ccss_tweets |>
sample_n(20) |>
relocate(text)👉 Your Turn ⤵
Use the code chunk below to take a sample of the NGSS tweets. Try to do it without looking at the code above first:
# YOUR CODE HEREStill of the same opinion?
- YOUR RESPONSE HERE
What else you notice about our data sets? Record a few observations that you think are relevant to our analysis or might be useful for future analyses.
- YOUR RESPONSE HERE
What questions do you have about these data sets? What are you still curious about?
- YOUR RESPONSE HERE
2c. Tidy Tweets
Now that we have the data needed to answer our questions, we still have a little bit of tidying to do to get it ready for analysis. This section will revisit some familiar functions from Module 1 and introduce a couple new functions:
Functions Used
dplyr functions
select()picks variables based on their names.slice()lets you select, remove, and duplicate rows.rename()changes the names of individual variables using new_name = old_name syntaxfilter()picks cases, or rows, based on their values in a specified column.
tidytext functions
unnest_tokens()splits a column into tokensanti_join()returns all rows from x without a match in y.
Subset Tweets
As you may have noticed, we have more data than we need for our analysis and should probably pare it down to just what we’ll use.
Let’s start with the CCSS tweets first. And since this is a family friendly case study, let’s use the filter() function introduced in previous labs to keep only those rows containing “possibly sensitive” language:
ccss_tweets_1 <- ccss_tweets |>
filter(possibly_sensitive == "FALSE")Now let’s use the select() function to select the following columns from our ccss_tweets_1 data frame:
textcontaining the tweet which is our primary data source of interestauthor_idof the user who created the tweetcreated_attimestamp for examining changes in sentiment over timeconversation_idfor examining sentiment by conversationsidfor the unique reference id for each tweet and useful for counts
ccss_tweets_2 <- ccss_tweets_1 |>
select(text,
author_id,
created_at,
conversation_id,
id)
ccss_tweets_2👉 Your Turn ⤵
Note: The select() function will also reorder your columns based on the order in which you list them.
Use the code chunk below to reorder the columns to your liking and assign to ccss_tweets_3:
ccss_tweets_3 <- ccss_tweets_2 |>
select(id,
text,
author_id,
created_at,
conversation_id)
ccss_tweets_3Add & Relocate Columns
Finally, since we are interested in comparing the sentiment of NGSS tweets with CSSS tweets, it would be helpful if we had a column to quickly identify the set of state standards with which each tweet is associated.
We’ll use the mutate() function introduced in previous case studies to create a new variable called standards to label each tweets as “ngss”:
ccss_tweets_4 <- mutate(ccss_tweets_2, standards = "ccss")
colnames(ccss_tweets_4)And just because it bothers me, I’m going to use the relocate() function to move the standards column to the first position so I can quickly see which standards the tweet is from:
ccss_tweets_5 <- relocate(ccss_tweets_4, standards)
colnames(ccss_tweets_5)Again, we could also have used the select() function to reorder columns like so:
ccss_tweets_5 <- ccss_tweets_4 |>
select(standards,
text,
author_id,
created_at,
conversation_id,
id)
colnames(ccss_tweets_5)Before moving on to the CCSS standards, let’s use the |> pipe operator and rewrite the code from our wrangling so there is less redundancy and it is easier to read:
# Search Tweets
ccss_tweets_clean <- ccss_tweets |>
filter(possibly_sensitive == "FALSE") |>
select(text, author_id, created_at, conversation_id, id) |>
mutate(standards = "ccss") |>
relocate(standards)
head(ccss_tweets_clean)👉 Your Turn ⤵
Recall from our Guiding Questions that we are interested in comparing word usage and public sentiment around both the Common Core and Next Gen Science Standards.
Create a new ngss_tweets_clean data frame consisting of the Next Generation Science Standards tweets we imported earlier by using the code directly above as a guide.
# YOUR CODE HERE
head(ngss_tweets_clean)Merge Data Frames
Finally, let’s combine our CCSS and NGSS tweets into a single data frame by using the base R union() function and simply supplying the data frames that you want to combine as arguments:
ss_tweets <- union(ccss_tweets_clean,
ngss_tweets_clean)
ss_tweetsNote that when creating a “union” like this (i.e. stacking one data frame on top of another), you should have the same number of columns in each data frame and they should be in the exact same order.
Alternatively, we could have used the bind_rows() function from {dplyr} as well:
ss_tweets <- bind_rows(ccss_tweets_clean,
ngss_tweets_clean)
ss_tweetsThe distinction between these two functions is that union by default removes any duplicate rows that might have shown up in both data frames.However, since both functions returned the same number of rows, it’s clear we do not have any duplicates.
If we wanted to verify, {dplyr} also has an intersect function to merge the two data frames, but only where they intersect(), or where they have duplicate rows.
ss_tweets_duplicate <- intersect(ccss_tweets_clean,
ngss_tweets_clean)
ss_tweets_duplicate👉 Your Turn ⤵
Finally, let’s take a quick look at both the head() and the tail() of this new ss_tweets data frame to make sure it contains both “ngss” and “ccss” standards and that the values for each are in the correct columns:
# YOUR CODE HERETokenize Text
We have a couple remaining steps to tidy our text that hopefully should feel familiar by this point. If you recall from Chapter 1 of Text Mining With R, Silge & Robinson describe tokens as:
A meaningful unit of text, such as a word, that we are interested in using for analysis, and tokenization is the process of splitting text into tokens. This one-token-per-row structure is in contrast to the ways text is often stored in current analyses, perhaps as strings or in a document-term matrix.
First, let’s tokenize our tweets by using the unnest_tokens() function to split each tweet into a single row to make it easier to analyze:
tweet_tokens <- ss_tweets |>
unnest_tokens(output = word,
input = text)Notice that we’ve included an additional argument in the call to unnest_tokens(). Specifically, we used the specialized “tweets” tokenizer in the tokens = argument that is very useful for dealing with Twitter text or other text from online forums in that it retains hashtags and mentions of usernames with the @ symbol.
Remove Stop Words
Now let’s remove stop words like “the” and “a” that don’t help us learn much about what people are tweeting about the state standards.
tidy_tweets <- tweet_tokens |>
anti_join(stop_words, by = "word")Notice that we’ve specified the by = argument to look for matching words in the word column for both data sets and remove any rows from the tweet_tokens dataset that match the stop_words dataset. Remember when we first tokenized our dataset I conveniently chose output = word as the column name because it matches the column name word in the stop_words dataset contained in the tidytext package. This makes our call to anti_join()simpler because anti_join() knows to look for the column named word in each dataset. However this wasn’t really necessary since word is the only matching column name in both datasets and it would have matched those columns by default.
Custom Stop Words
Before wrapping up, let’s take a quick count of the most common words in tidy_tweets data frame:
count(tidy_tweets, word, sort = T)Notice that the nonsense words like “t.co”, “https”, and “amp” occur in our top tens words. If we use the filter() function and `grep() query from Module 1 on our tweets data frame, we can see that “amp” seems to be some sort of html residue that we might want to get rid of.
filter(ss_tweets, grepl('amp', text))Let’s rewrite our stop word code to add a custom stop word to keep only rows that do NOT ! have tokens in the word column equal == to “amp” or “https” or “t.co”:
tidy_tweets <- tweet_tokens |>
anti_join(stop_words, by = "word") |>
filter(!word == "amp",
!word == "https",
!word == "t.co")Note that we could simplify and extend this filter to weed out any additional words that don’t carry much meaning but may skew our data by being so prominent, including numerical values “1” through “9.”
Run the following code to create a vector of words to remove and the by using the c() combine function and the str_detect() function from the dplyr package to remove
tidy_tweets <- tweet_tokens %>%
anti_join(stop_words, by = "word") %>%
filter(!word %in% c("amp", "https", "t.co", as.character(1:100))
) # Exclude any words "in" that vector including characters 1-9Now let’s run our counts again and confirm they were removed:
count(tidy_tweets, word, sort = T)Much better!
👉 Your Turn ⤵
We’ve created some unnecessarily lengthy code to demonstrate some of the steps in the tidying process.
Complete the following code to rewrite the tokenization and removal of stop words processes into a more compact series of commands and save your data frame as tidy_tweets.
tidy_tweets <- ss_tweets |>
# YOUR CODE HERE
tidy_tweets2c. Add Sentiment Values
Now that we have our tweets nice and tidy, we’re almost ready to begin exploring public sentiment around the CCSS and NGSS standards. For this part of our workflow we introduce two new functions from the {tidytext} and {dplyr} packages respectively:
get_sentiments()returns specific sentiment lexicons with the associated measures for each word in the lexiconinner_join()return all rows fromxwhere there are matching values iny, and all columns fromxandy.
For a quick overview of the different join functions with helpful visuals, visit: https://statisticsglobe.com/r-dplyr-join-inner-left-right-full-semi-anti
And for a more in-depth look at the different tidyverse joins, visit the chapter on joins from R for Data Science, at: https://r4ds.hadley.nz/joins.html
Get Sentiments
Recall from our readings that sentiment analysis tries to evaluate words for their emotional association. Silge & Robinson point out that,
… one way to analyze the sentiment of a text is to consider the text as a combination of its individual words and the sentiment content of the whole text as the sum of the sentiment content of the individual words.
As our Readings & Discussion illustrate, this isn’t the only way to approach sentiment analysis, but it is an easier entry point into sentiment analysis and often-used in practice.
The {tidytext} package provides access to several sentiment lexicons based on unigrams, i.e., single words. These lexicons contain many English words and the words are assigned scores or categories for positive/negative sentiment, and some include categories for emotions emotions like joy, anger, sadness, and so forth.
The three general-purpose lexicons we’ll focus on are:
AFINNassigns words with a score that runs between -5 and 5, with negative scores indicating negative sentiment and positive scores indicating positive sentiment.bingcategorizes words in a binary fashion into positive and negative categories.nrccategorizes words in a binary fashion (“yes”/“no”) into categories of positive, negative, anger, anticipation, disgust, fear, joy, sadness, surprise, and trust.
Important
Note that if this is your first time using the AFINN and NRC lexicons, you’ll be prompted to download both. Respond “yes” to the prompt in the Console by entering “1” and the NRC and AFINN lexicons will download. You’ll only have to do this the first time you use the NRC lexicon.
Let’s take a quick look at each of these lexicons using the get_sentiments() function and assign them to their respective names for later use:
afinn <- get_sentiments("afinn")
afinnbing <- get_sentiments("bing")
bingnrc <- get_sentiments("nrc")
nrcAnd just out of curiosity, let’s take a look at the loughran lexicon, which categorizes words with an emphasis on financial and economic contexts, labeling words as positive, negative, uncertainty, litigious, etc.:
loughran <- get_sentiments("loughran")
loughran❓Question
Take a quick look at Chapter 2 from Text Mining with Rand answer the following questions:
- How were these sentiment lexicons actually constructed and validated?
- YOUR RESPONSE HERE
- Why should we be cautious when using and interpreting them?
- YOUR RESPONSE HERE
Join Sentiments
We’ve reached the final step in our data wrangling process before we can begin exploring our data to address our questions.
In the previous section, we used anti_join() to remove stop words in our dataset. For sentiment analysis, we’re going use the inner_join() function to do something similar. However, instead of removing rows that contain words matching those in our stop words dictionary, inner_join() allows us to keep only the rows with words that match words in our sentiment lexicons, or dictionaries, along with the sentiment measure for that word from the sentiment lexicon.
Let’s use inner_join() to combine our two tidy_tweets and afinn data frames, keeping only rows with matching data in the word column:
sentiment_afinn <- inner_join(tidy_tweets, afinn, by = "word")
sentiment_afinn |>
select(word, value)Notice that each word in your sentiment_afinn data frame now contains a value ranging from -5 (very negative) to 5 (very positive).
And just out of curiosity, let’s take a look at the bing, and loughran lexicons, which use word categories instead of numerical values to classify text by sentiment:
👉 Your Turn ⤵
Create a sentiment_nrc data frame using the code above.
❓Question
- What do you notice about the change in the number of observations (i.e. words) between the
tidy_tweetsand data frames with sentiment values attached?- YOUR RESPONSE HERE
- Why do you think this happened did this happen?
- YOUR RESPONSE HERE
3. EXPLORE
Now that we have our tweets tidied and sentiments joined, we’re ready for a little data exploration. As highlighted in Module 1, calculating summary statistics, data visualization, and feature engineering (the process of creating new variables from a dataset) are a key part of exploratory data analysis. One goal in this phase is explore questions that drove the original analysis and develop new questions and hypotheses to test in later stages. Topics addressed in Section 3 include:
- Time Series. We take a quick look at the date range of our tweets and compare number of postings by standards.
- Sentiment Summaries. We put together some basic summaries of our sentiment values in order to compare public sentiment
3a. Time Series
Before we dig into sentiment, let’s use the handy {dplyr} and {ggplot2} packaages to take a very quick look at the number of daily tweets over the first 5 months of 2020:
daily_tweets <- ss_tweets %>%
mutate(tweet_date = as.Date(created_at)) %>%
group_by(tweet_date) %>%
summarise(count = n())
# 4. Plot a line chart of the number of tweets over time
ggplot(daily_tweets, aes(x = tweet_date, y = count)) +
geom_line(color = "#CC0000") +
labs(
title = "Number of Tweets Over Time",
x = "2020",
y = "Tweet Count")Now let’s quickly unpack what our code just did:
Convert to date: the
mutate(tweet_date = as.Date(created_at))created a new column,tweet_date, by extracting just the date portion from thecreated_atcolumn.Group by date: The
group_by(tweet_date)groups all tweets by their date.Count tweets: The
summarise(count = n())counts the number of tweets per date, returning a daily summary in daily_tweets.Plot the results: The
ggplot(...) + geom_line(...)code creates a line chart with thetweet_dateon the x-axis and the tweetcounton the y-axis, coloring the line in red#CC0000and adding axis labels and a title.
👉 Your Turn ⤵
Now recycle and modify the code from above to plot each standard separately so we can compare the number of tweets over time by Next Generation Science and Common Core standard:
# YOUR CODE HERE3b. Sentiment Summaries
Since our primary goals is to compare public sentiment around the NGSS and CCSS state standards, in this section we put together some basic numerical summaries using our different lexicons to see whether tweets are generally more positive or negative for each standard as well as differences between the two. To do this, we revisit the following dplyr functions:
count()lets you quickly count the unique values of one or more variablesgroup_by()takes a data frame and one or more variables to group bysummarise()creates a numerical summary of data using arguments likemean()andmedian()mutate()adds new variables and preserves existing ones
And introduce one new function:
pivot_wider()“widens” data, increasing the number of columns and decreasing the number of rows. The inverse transformation ispivot_longer().
Sentiment Counts
Let’s start with bing, our simplest sentiment lexicon, and use the count function to count how many times in our sentiment_bing data frame “positive” and “negative” occur in sentiment column and :
summary_bing <- count(sentiment_bing, sentiment, sort = TRUE)Collectively, it looks like our combined dataset has more positive words than negative words.
summary_bingSince our main goal is to compare positive and negative sentiment between CCSS and NGSS, let’s use the group_by function again to get sentiment summaries for NGSS and CCSS separately:
summary_bing <- sentiment_bing |>
group_by(standards) |>
count(sentiment)
summary_bingLooks like CCSS have far more negative words than positive, while NGSS skews much more positive. So far, pretty consistent with Rosenberg et al. findings!!!
Compare Sentiment Counts
Our last step will be calculate a single sentiment “score” for our tweets that we can use for quick comparison and create a new variable indicating which lexicon we used.
First, let’s untidy our data a little by using the pivot_wider function from the tidyr package to transform our sentiment column into separate columns for negative and positive that contains the n counts for each:
summary_bing <- sentiment_bing |>
group_by(standards) |>
count(sentiment, sort = TRUE) |>
pivot_wider(
names_from = sentiment,
values_from = n)
summary_bingAgain, let’s quickly unpack the code we just used:
Group by standards: The
group_by()function splits the data so each subsequent operation works within each standard.Count sentiment: For each of the
standards, thecount()function calculates how many times each sentiment appears. The sort = TRUE argument orders results by frequency.Pivot to wide format: Finally, the
pivot_wider()function converts the data so each unique sentiment becomes a separate column (using names_from = sentiment), and the count of those sentiments fills the corresponding cells (using values_from = n).
Finally, we’ll use the mutate function to create two new variables: sentiment and lexicon so we have a single sentiment score and the lexicon from which it was derived:
summary_bing <- sentiment_bing |>
group_by(standards) |>
count(sentiment, sort = TRUE) |>
pivot_wider(
names_from = sentiment,
values_from = n) |>
mutate(sentiment = positive - negative) |>
mutate(lexicon = "bing") |>
relocate(lexicon)
summary_bingThere we go, now we can see that CCSS scores negative, while NGSS is overall positive.
Compute Sentiment Scores
Now let’s calculate a quick score for using the afinn lexicon. Recall that AFINN provides a value from -5 to 5 for each:
head(sentiment_afinn, n = 10) |>
select(word, value)To calculate late a summary score, we will need to first group our data by standards again and then use the summarise function to create a new sentiment variable by adding all the positive and negative scores in the value column:
summary_afinn <- sentiment_afinn |>
group_by(standards) |>
summarise(sentiment = sum(value)) |>
mutate(lexicon = "AFINN") |>
relocate(lexicon)
summary_afinnAgain, CCSS is overall negative while NGSS is overall positive!
👉 Your Turn ⤵
For your final task for this case study is to calculate a single sentiment score for NGSS and CCSS using either the remaining nrc or AFINN lexicons.
Tip
The nrc lexicon contains “positive” and “negative” values just like bing, but also includes values like “trust” and “sadness” as shown below. If you use nrc, you will need to use the filter() function to select rows that only contain “positive” and “negative.”
❓Question
- How do these results compare to our findings from the
binglexicon? Include at least two observations in your response.- OBSERVATION 1
- OBSERVATION 1
3c. Visualizing Sentiment
Let’s try and replicate as closely as possible the approach Rosenberg et al. used in their analysis. To do that, we can recycle some R code used in section 2a. Tidy Tweets.
First, let’s rebuild the tweets dataset from our ngss_tweets and ccss_tweets and select both the id that is unique to each tweet, and the text column which contains the actual post:
ngss_text <-
ngss_tweets |>
select(id, text) |>
mutate(standards = "ngss") |>
relocate(standards)
ccss_text <-
ccss_tweets |>
select(id, text) |>
mutate(standards = "ccss") |>
relocate(standards)
tweets <- bind_rows(ngss_text, ccss_text)
tweetsThe id variable is important because like Rosenberg et al., we want to calculate an overall sentiment score for each tweet, rather than for each word. Later we’ll explore the VADER sentiment model that takes a more sophisticated but similar approach.
Before we get that far however, let’s to tidy our tweets again and attach our sentiment scores.
Note that the closest lexicon we have available in our tidytext package to the SentiStrength lexicon used by Rosenberg is the AFINN lexicon which also uses a -5 to 5 point scale.
So let’s use unnest_tokens to tidy our tweets, remove stop words, and add afinn scores to each word similar to what we did in section 2c. Add Sentiment Values:
sentiment_afinn <- tweets |>
unnest_tokens(output = word,
input = text) |>
anti_join(stop_words, by = "word") |>
filter(!word == "amp") |>
inner_join(afinn, by = "word")
sentiment_afinnNext, let’s calculate a single score for each tweet. To do that, we’ll use the by now familiar group_by and summarize
afinn_score <- sentiment_afinn |>
group_by(standards, id) |>
summarise(value = sum(value))
afinn_scoreAnd like Rosenberg et al., we’ll add a flag for whether the tweet is “positive” or “negative” using the mutate function to create a new sentiment column to indicate whether that tweets was positive or negative.
To do this, we introduced the new if_else function from the dplyr package. This if_else function adds “negative” to the sentiment column if the score in the value column of the corresponding row is less than 0. If not, it will add a “positive” to the row.
afinn_sentiment <- afinn_score |>
filter(value != 0) |>
mutate(sentiment = if_else(value < 0, "negative", "positive"))
afinn_sentimentNote that since a tweet sentiment score equal to 0 is neutral, I used the filter function to remove it from the dataset.
Finally, we’re ready to compute our ratio. We’ll use the group_by function and count the number of tweets for each of the standards that are positive or negative in the sentiment column. Then we’ll use the spread function to separate them out into separate columns so we can perform a quick calculation to compute the ratio.
afinn_ratio <- afinn_sentiment |>
group_by(standards) |>
count(sentiment) |>
spread(sentiment, n) |>
mutate(ratio = negative/positive)
afinn_ratioFinally, let’s create a simple pie chart that we can use to visually communicate the proportion of positive and negative tweets:
afinn_counts <- afinn_sentiment |>
group_by(standards) |>
count(sentiment) |>
filter(standards == "ngss")
afinn_counts |>
ggplot(aes(x="", y=n, fill=sentiment)) +
geom_bar(width = .6, stat = "identity") +
labs(title = "Next Gen Science Standards",
subtitle = "Proportion of Positive & Negative Tweets") +
coord_polar(theta = "y") +
theme_void()👉 Your Turn ⤵
In the code chunk below, replicate this process to create a similar pie chart for the CCSS tweets:
# YOUR CODE HERE4. MODEL
As highlighted in Chapter 3 of Data Science in Education Using R, the Model step of the data science process entails “using statistical models, from simple to complex, to understand trends and patterns in the data.” The authors note that while descriptive statistics and data visualization during the Explore step can help us to identify patterns and relationships in our data, statistical models can be used to help us determine if relationships, patterns and trends are actually meaningful.
Recall from the PREPARE section that Rosenberg et al. (2020) study was guided by the following research questions:
What public sentiment is expressed on the social media platform Twitter toward the NGSS?
What factors explain variation in this public sentiment?
Similar to our sentiment summary using the AFINN lexicon, the Rosenberg et al. study used the -5 to 5 sentiment score from the SentiStrength lexicon to answer RQ1. To address RQ2 the authors used a mixed-effects model (also known as multi-level or hierarchical linear models via the {lme4} package in R.
Collectively, the authors found that:
- The SentiStrength scale indicated an overall neutral sentiment for tweets about the Next Generation Science Standards.
- Teachers were more positive in their posts than other participants.
- Posts including #NGSSchat that were posted outside of chats were slightly more positive relative to those that did not include the #NGSSchat hashtag.
- The effect upon individuals of being involved in the #NGSSchat was positive, suggesting that there is an impact on individuals—not tweets—of participating in a community focused on the NGSS.
- Posts about the NGSS became substantially more positive over time.
Although we won’t be using a mixed-effects model to identify factors that may help to difference in public sentiment, let’s take a look at a popular rule-based model that designed for assigning a sentiment score to an entire tweet, rather than individual words.
Come to the Dark Side

As noted in the PERPARE section, the {vader} package is for the Valence Aware Dictionary for sEntiment Reasoning (VADER), a rule-based model for general sentiment analysis of social media text and specifically attuned to measuring sentiment in microblog-like contexts such as Twitter.
The VADER assigns a number of different sentiment measures based on the context of the entire social-media post or in our case a tweet. Ultimately, however, these measures are based on a sentiment lexicon similar to those you just saw above. One benefit of using VADER rather than the approaches described by Silge and Robinson is that we use it with our tweets in their original format and skip the text preprocessing steps demonstrated above.
One drawback to VADER is that it can take a little while to run since it’s computationally intensive. Instead of analyzing tens of thousands of tweets, let’s read in our original ccss-tweets.csv and take instead just a sample of 500 “untidy” CCSS tweets using the sample_n() function:
ccss_sample <- read_csv("data/ccss-tweets.csv") |>
sample_n(500)
ccss_sampleNote above that we passed our read_csv() output directly to our sample() function rather than saving a new data frame object, passing that to sample_n(), and saving as another data frame object. The power of the |> pipe!
On to the Dark Side. The {vader} package basically has just one function, vader_df() that does one thing and expects just one column from one frame. He’s very single minded! Let’s give VADER our ccss_sample data frame and include the $ operator to include only the text column containing our tweets.
Note, this may take a little while to run.
vader_ccss <- vader_df(ccss_sample$text)
vader_ccss❓Question
Take a look at vader_summary data frame using the View() function in the console and sort by most positive and negative tweets.
Does it generally seem to accurately identify positive and negative tweets? Could you find any that you think were mislabeled?
- YOUR RESPONSE HERE
Hutto, C. & Gilbert, E. (2014) provide an excellent summary of the VADER package on their GitHub repository and I’ve copied and explanation of the scores below:
- The
compoundscore is computed by summing the valence scores of each word in the lexicon, adjusted according to the rules, and then normalized to be between -1 (most extreme negative) and +1 (most extreme positive). This is the most useful metric if you want a single unidimensional measure of sentiment for a given sentence. Calling it a ‘normalized, weighted composite score’ is accurate.
NOTE: The compound score is the one most commonly used for sentiment analysis by most researchers, including the authors.
Let’s take a look at the average compound score for our CCSS sample of tweets:
mean(vader_ccss$compound)❓Question
Overall, do your CCSS tweets sample lean slightly negative or positive or neutral? Is this what you expected?
- YOUR RESPONSE HERE
What if we wanted to compare these results more easily to our other sentiment lexicons just to check if result are fairly consistent?
The author’s note that it is also useful for researchers who would like to set standardized thresholds for classifying sentences as either positive, neutral, or negative. Typical threshold values are:
positive sentiment:
compoundscore >= 0.05neutral sentiment: (
compoundscore > -0.05) and (compoundscore < 0.05)negative sentiment:
compoundscore <= -0.05
Let’s give that a try and see how things shake out:
vader_ccss_summary <- vader_ccss |>
mutate(sentiment = ifelse(compound >= 0.05, "positive",
ifelse(compound <= -0.05, "negative", "neutral"))) |>
count(sentiment, sort = TRUE) |>
spread(sentiment, n) |>
relocate(positive) |>
mutate(ratio = negative/positive)
vader_ccss_summaryNot quite as bleak as we might have expected according to VADER! But then again, VADER brings an entirely different perspective coming from the dark side
👉 Your Turn ⤵
In the code chunk below, try using VADER to perform a sentiment analysis of the NGSS tweets and see how they compare:
# YOUR CODE HERE❓Question
How do our results compare to the CSSS sample of tweets?
- YOUR RESPONSE HERE
5. COMMUNICATE
The final(ish) step in our workflow/process is sharing the results of analysis with wider audience. Krumm et al. (2018) outlined the following 3-step process for communicating with education stakeholders what you have learned through analysis:
- Select. Communicating what one has learned involves selecting among those analyses that are most important and most useful to an intended audience, as well as selecting a form for displaying that information, such as a graph or table in static or interactive form, i.e. a “data product.”
- Polish. After creating initial versions of data products, research teams often spend time refining or polishing them, by adding or editing titles, labels, and notations and by working with colors and shapes to highlight key points.
- Narrate. Writing a narrative to accompany the data products involves, at a minimum, pairing a data product with its related research question, describing how best to interpret the data product, and explaining the ways in which the data product helps answer the research question.
5a. Select
Remember that the questions of interest that we want to focus on our for our selection, polishing, and narration include:
- What is the public sentiment expressed toward the NGSS?
- How does sentiment for NGSS compare to sentiment for CCSS?
To address questions 1 and 2, I’m going to focus my analyses, data products and sharing format on the following:
- Analyses. For RQ1, I’m want to try and replicate as closely as possible the analysis by Rosenberg et al. so I will clean up my analysis and calculate a single sentiment score using the AFINN Lexicon for the entire tweet and label it positive or negative based on that score. I also want to highlight how regardless of the lexicon selected, NGSS tweets contain more positive words than negative, so I’ll also polish my previous analyses and calculate percentages of positive and negative words for the
- Data Products. I know these are shunned in the world of data viz, but I think a pie chart will actually be an effective way to quickly communicate the proportion of positive and negative tweets among the Next Generation Science Standards. And for my analyses with the
bing,nrc, andloughanlexicons, I’ll create some 100% stacked bars showing the percentage of positive and negative words among all tweets for the NGSS and CCSS. - Format. Similar to Module 1, I’ll be using Quarto again to create a
revealjsslide deck. or short report that documents our independent analysis. Quarto files can also be used to create a wide range of outputs and formats, including polished PDF or Word documents, websites, web apps, journal articles, online books, interactive tutorials and more.
5b. Polish
For my polished chart I also wanted to address Question 2 and compare the percentage of positive and negative words contained in the corpus of tweets for the NGSS and CCSS standards using the four different lexicons to see how sentiment compares based on lexicon used.
I’ll begin by polishing my previous summaries and creating identical summaries for each lexicon that contains the following columns: method, standards, sentiment, and n, or word counts:
summary_afinn2 <- sentiment_afinn |>
group_by(standards) |>
filter(value != 0) |>
mutate(sentiment = if_else(value < 0, "negative", "positive")) |>
count(sentiment, sort = TRUE) |>
mutate(method = "AFINN")
summary_bing2 <- sentiment_bing |>
group_by(standards) |>
count(sentiment, sort = TRUE) |>
mutate(method = "bing")
summary_nrc2 <- sentiment_nrc |>
filter(sentiment %in% c("positive", "negative")) |>
group_by(standards) |>
count(sentiment, sort = TRUE) |>
mutate(method = "nrc")
summary_loughran2 <- sentiment_loughran |>
filter(sentiment %in% c("positive", "negative")) |>
group_by(standards) |>
count(sentiment, sort = TRUE) |>
mutate(method = "loughran") Next, I’ll combine those four data frames together using the bind_rows function again:
summary_sentiment <- bind_rows(summary_afinn2,
summary_bing2,
summary_nrc2,
summary_loughran2) |>
arrange(method, standards) |>
relocate(method)
summary_sentimentThen I’ll create a new data frame that has the total word counts for each set of standards and each method and join that to my summary_sentiment data frame:
total_counts <- summary_sentiment |>
group_by(method, standards) |>
summarise(total = sum(n))
sentiment_counts <- left_join(summary_sentiment, total_counts)
sentiment_countsFinally, I’ll add a new row that calculates the percentage of positive and negative words for each set of state standards:
sentiment_percents <- sentiment_counts |>
mutate(percent = n/total * 100)
sentiment_percentsNow that I have my sentiment percent summaries for each lexicon, I’m going great my 100% stacked bar charts for each lexicon:
sentiment_percents |>
ggplot(aes(x = standards, y = percent, fill=sentiment)) +
geom_bar(width = .8, stat = "identity") +
facet_wrap(~method, ncol = 1) +
coord_flip() +
labs(title = "Public Sentiment on Twitter",
subtitle = "The Common Core & Next Gen Science Standards",
x = "State Standards",
y = "Percentage of Words") +
theme_minimal()And finished! The chart above clearly illustrates that regardless of sentiment lexicon used, the NGSS contains more positive words than the CCSS lexicon.
5c. Narrate
With our “data products” cleanup complete, we can start pulling together a quick presentation to share with the class. We’ve already seen what a more formal journal article looks like in the PREPARE section of this case study. For your Independent Analysis assignment for Module 2, you’ll be creating either a simple report or slide deck to share out some key findings from our analysis.
Regardless of whether you plan to talk us through your analysis and findings with a presentation or walk us through with a brief written report, your assignment should address the following questions:
- Purpose. What question or questions are guiding your analysis? What did you hope to learn by answering these questions and why should your audience care about your findings?
- Methods. What data did you selected for analysis? What steps did you take took to prepare your data for analysis and what techniques you used to analyze your data? These should be fairly explicit with your embedded code.
- Findings. What did you ultimately find? How do your “data products” help to illustrate these findings? What conclusions can you draw from your analysis?
- Discussion. What were some of the strengths and weaknesses of your analysis? How might your audience use this information? How might you revisit or improve upon this analysis in the future?
References
Rosenberg, Joshua, Conrad Borchers, Elizabeth B Dyer, Daniel Anderson, and Christian Fischer. 2020. “Understanding Public Sentiment about Educational Reforms: The Next Generation Science Standards on Twitter,” October. http://dx.doi.org/10.31219/osf.io/xymsd.
Silge, Julia, and David Robinson. 2017. Text Mining with r: A Tidy Approach. " O’Reilly Media, Inc.". https://www.tidytextmining.com.